

こんにちは。AI index、運営者の「りょう」です。
最近、ニュースやSNSでも「生成AI」という言葉を見ない日はないくらい、GoogleのGeminiを使う機会が急速に増えてきましたね。メールの下書きを作ったり、アイデア出しを手伝ってもらったりと、私たちの生活や仕事を劇的に便利にしてくれる頼もしい相棒ですが、一方で「入力したデータがどのように扱われるのか」について、少し不安を感じたことはありませんか?

特に、「自分のプライベートな会話や、会社の大事な情報が勝手にAIの学習に使われてしまうのではないか」という懸念は、決して考えすぎではありません。実際、過去には他社のAIサービスで情報漏洩に近い事例も発生しており、プライバシーを守るために履歴を残さない設定にしたい、あるいは業務利用において無料で使いつつも安全性を確保したいと考えている方は非常に多いのです。
この記事では、Geminiに学習させないための具体的な設定手順から、履歴を消すことと学習データから除外することの技術的な違い、そしてビジネスシーンで絶対にやってはいけないNG行動まで、私自身の検証結果も交えながら徹底的に解説していきます。
- 個人アカウントで直ちに実行できる具体的な学習防止設定の手順
- 履歴を消すことと学習させないことの技術的な違いとリスク
- Samsung事件などの事例から学ぶ業務利用時の情報漏洩リスク
- APIや法人向けプランにおけるデータプライバシーの仕組みと対策
目次
Geminiに学習させない設定手順
まずは、私たちが普段プライベートで使っている個人のGoogleアカウント(無料版や個人用Gemini Advanced)でGeminiを利用する際、どのようにすればデータを学習させずに済むのか、その具体的な設定方法と背後にある仕組みについて深掘りしていきます。設定ひとつ変えるだけで、AIに対する安心感が大きく変わりますので、ぜひスマホやPCを片手にチェックしてみてください。
履歴を残さない設定と学習の違い
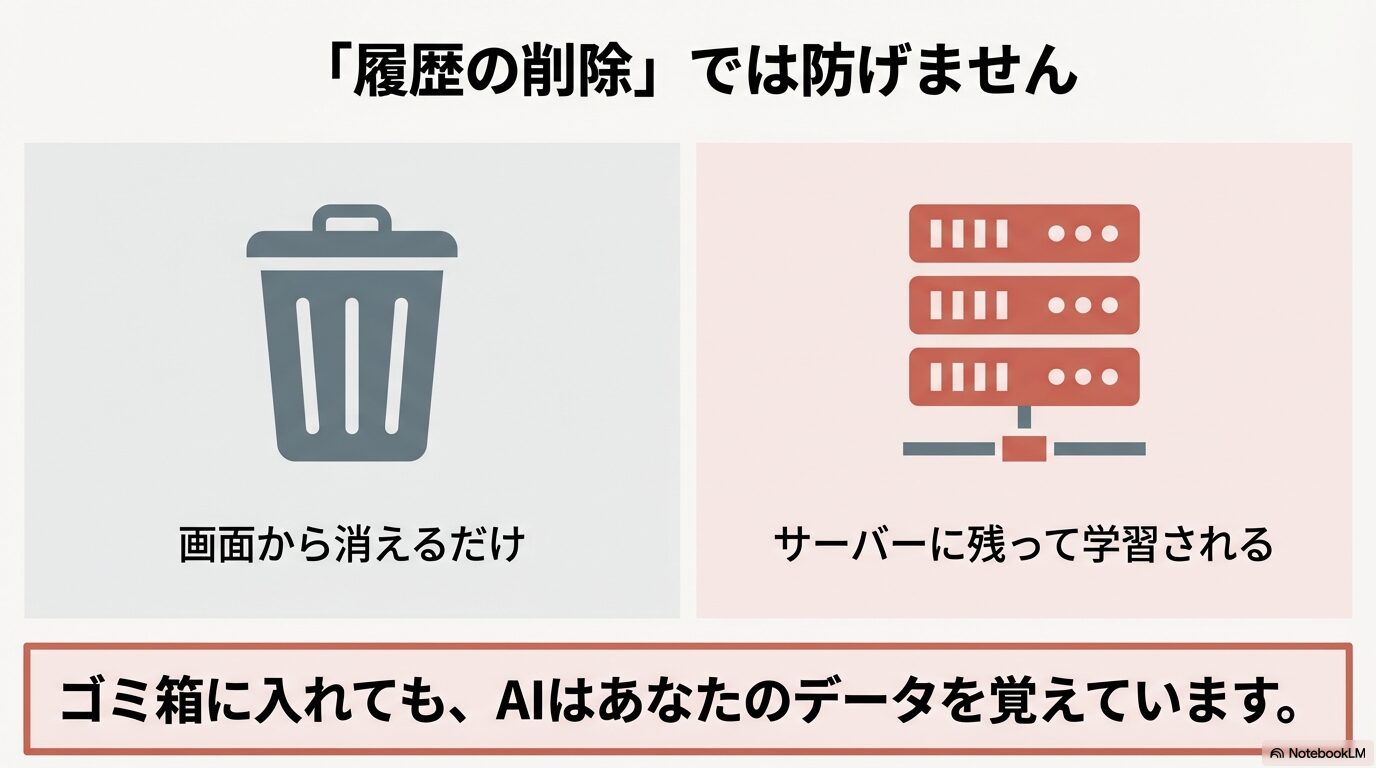
多くのユーザーが陥りがちな最大の誤解、それは「チャットの履歴をゴミ箱アイコンで削除すれば、Googleのサーバーからもデータが消えて学習されなくなる」と思い込んでしまうことです。実はこれ、技術的な仕組みとしては明確に区別されており、表面上の履歴を消しただけでは不十分なケースがほとんどなのです。
まず、私たちが普段画面で見ているチャット履歴は「コンテキスト(文脈)」と呼ばれるものです。これは、AIが「さっきの質問の続きだけど…」といった会話の流れを理解するために一時的に保持している短期記憶のようなものです。ユーザーがブラウザで履歴を削除すると、このコンテキストへのアクセス権は失われ、あなた自身の画面からはきれいさっぱり消え去ります。
しかし、「学習データ」というのはこれとは全く別物です。Googleは、AIモデル(LLM)をより賢く、より自然な対話ができるように進化させるために、ユーザーとの対話データをサーバー側のデータベースに長期的に保存し、「再学習(ファインチューニング)」や「評価用データセット」として利用します。このプロセスは、あなたが画面上で履歴を削除する操作とは連動していない場合が多く、設定で明示的に「保存しない」と宣言しない限り、サーバーの奥底にデータが残り続ける可能性があるのです。
ここが重要!
画面上の「履歴削除」はあくまで「あなたの見え方」を整理する機能であり、「Googleによるデータの利用」を停止する機能ではありません。設定自体が「アクティビティON」になっていれば、そのデータはすでに学習用のパイプラインに乗って処理されている可能性があります。
つまり、「学習させない」という目的を達成するためには、単に目の前の履歴を消すという対症療法ではなく、データの入り口を閉じるような根本的な設定の見直しが必要不可欠なんですね。これを理解していないと、「毎回履歴を消しているから大丈夫」と油断して、機密情報を入力してしまうリスクがあります。
アクティビティをオフにする変更手順
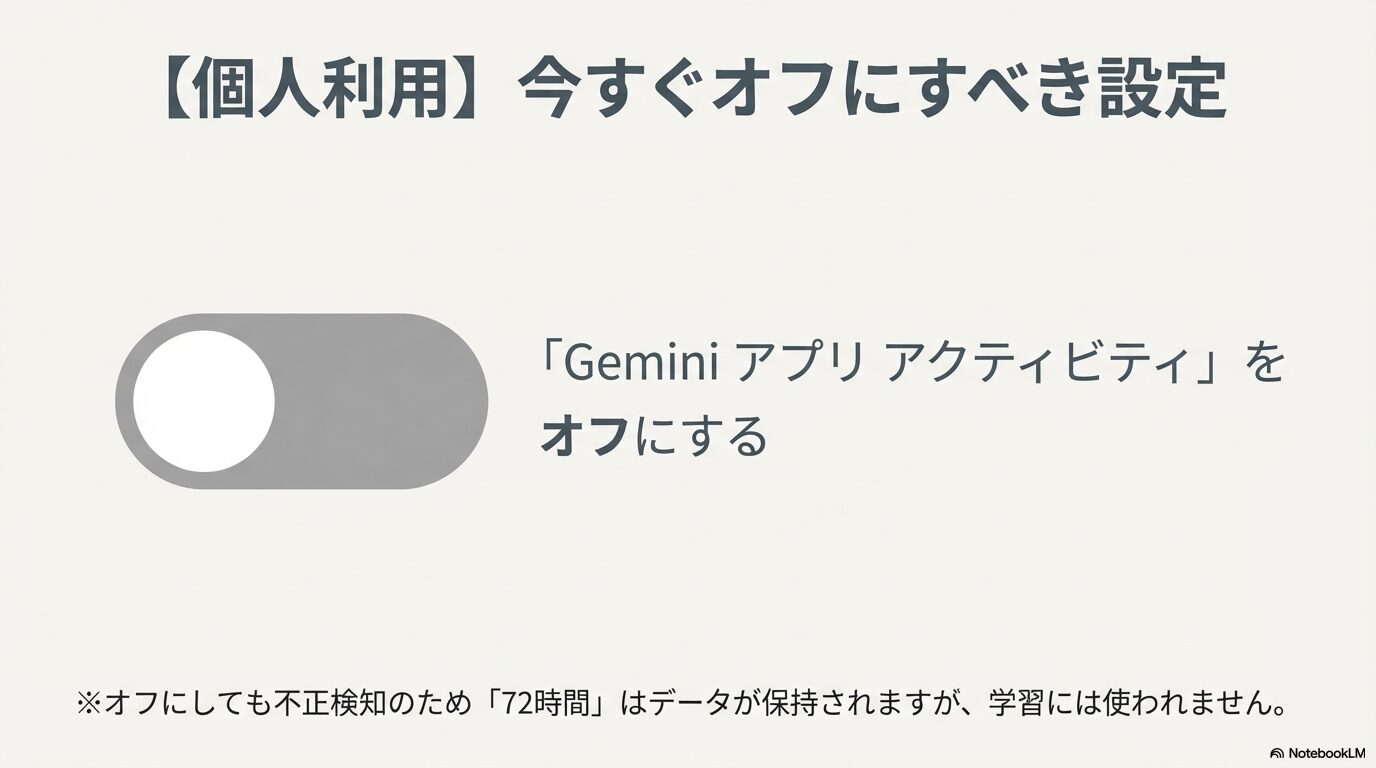
では、具体的にどうすればいいのでしょうか。Geminiにデータを学習させないための最も確実かつ公式に推奨されている方法は、「Gemini アプリ アクティビティ」という設定項目を無効化(オフ)にすることです。多くのアカウントでは、利便性を高めるためにデフォルトでこれが「オン」になっていることが多いので、手動で切り替える必要があります。
PCとスマートフォン、どちらからでも設定可能ですが、以下の手順で確実に設定を確認してみてください。
- まず、ブラウザでGemini(gemini.google.com)にアクセスするか、スマホのGoogleアプリを開きます。
- 画面左下の「アクティビティ」または、右上のアイコンから「設定」>「アクティビティ」へと進みます。
- 画面上部に「Gemini アプリ アクティビティ」という項目が表示されます。ここのステータスが「オン」になっている場合は、クリックして設定画面に入ります。
- 「オフにする」または「オフにしてアクティビティを削除」というオプションを選択します。これから先のデータだけでなく、過去のデータも学習に使われたくない場合は、迷わず「削除」の方を選んでください。
この設定を行うことで、あなたの入力した会話データはGoogleアカウントに紐付いた状態では保存されなくなります。Googleの公式ヘルプにも、この設定がオフの場合、入力された会話は「モデルのトレーニングには利用されない」と明記されています。ただし、ここで一つ重要な技術的な注意点があります。
72時間保持ルールについて
アクティビティをオフにしても、その瞬間にデータが全消去されるわけではありません。Googleはスパムや不正利用の検知、および法的な対応のために、設定オフの状態でも「最大72時間」はデータを一時的に保持する仕様になっています。この期間中は学習には使われませんが、サーバー上には存在しているという点は、セキュリティ意識の高い方なら知っておくべき事実です。
また、この設定をオフにすることのデメリットとして、過去のチャット履歴を遡って確認できなくなるほか、GmailやGoogleドライブと連携する「Gemini 拡張機能」の多くが動作しなくなる点が挙げられます。プライバシーを最優先するか、AIの便利機能をフル活用するか、ご自身の利用スタイルに合わせて天秤にかける必要があります。
入力データ学習のリスクと個人情報
「なぜそこまでして学習を拒否する必要があるの? 私の今日のランチの相談なんて、誰に見られても構わないよ」と疑問に思う方もいるかもしれません。確かに日常会話程度なら問題ないかもしれませんが、学習されることの最大のリスクは、AIの改善プロセスに「生身の人間(レビュアー)」が関わっているという事実にあります。
生成AIの回答精度を向上させるためには、「強化学習(RLHF)」というプロセスが不可欠です。これは、AIが生成した回答に対して、人間が良いか悪いかを評価したり、理想的な回答例を修正して教え込んだりする作業です。Googleの規約やプライバシーハブには、サービスの品質向上のために、訓練を受けた人間のレビュアーがユーザーの会話の一部を閲覧し、評価を行っていることが明記されています。
もちろん、Google側でもプライバシー保護のために、レビュアーがデータを見る前にGoogleアカウントやメールアドレスなどの個人識別情報を切り離す「匿名化処理」を行っています。しかし、ここに落とし穴があります。アカウント情報が切り離されていても、プロンプト(入力文)そのものに含まれる情報は消えません。
例えば、あなたが以下のような入力をしたと想像してみてください。
「東京都〇〇区△△マンションの理事会規約について相談ですが、理事長の田中さんが…」
「私の病歴は〇〇で、現在服用している薬は××ですが…」
「社外秘のプロジェクトコード『Project-X』の進捗遅れを取り戻すコードを書いて」
いかがでしょうか。たとえ送信者の名前が「匿名ユーザー」になっていたとしても、入力された文章の中身を見れば、どこの誰の話なのか、あるいはどこの企業の機密情報なのかが、文脈から推測できてしまうリスクはゼロではありません。これが、個人情報保護の観点から「学習させない設定」が強く推奨される理由です。

出典情報
Googleの公式ヘルプページにおいても、人間のレビュアーによるデータの処理と、プライバシー保護の仕組みについて詳細に説明されています。特に機密情報の入力には注意が必要です。
(出典:Google Gemini アプリのプライバシー ハブ)
情報漏洩事例から学ぶ危険性
「AIに学習されることで情報が漏れる」というのは、単なる理論上の話ではありません。実際に、生成AIの黎明期において、学習機能が原因で企業レベルの情報漏洩リスクが顕在化した有名な事例があります。それが、2023年に発生し世界中に衝撃を与えたSamsung(サムスン)のケースです。
当時、Samsungの半導体部門において、エンジニアたちが業務効率化のためにChatGPT(当時はまだGeminiの前身であるBardが普及する前でしたが、全てのLLMに共通する普遍的なリスクです)を利用していました。彼らは悪意を持っていたわけではなく、ただ仕事を早く終わらせたかったのです。そこで、バグ修正が必要な機密ソースコードや、スマートフォンの通話録音から文字起こしした極秘の戦略会議の内容を、そのままAIのチャット欄に貼り付けてしまいました。
その結果、何が起きたでしょうか。当時のOpenAIの仕様では、入力されたデータはデフォルトで学習データとして利用される設定になっていました。つまり、Samsungの独自技術や未公開の戦略情報が、AIの知識の一部としてサーバーに取り込まれてしまったのです。
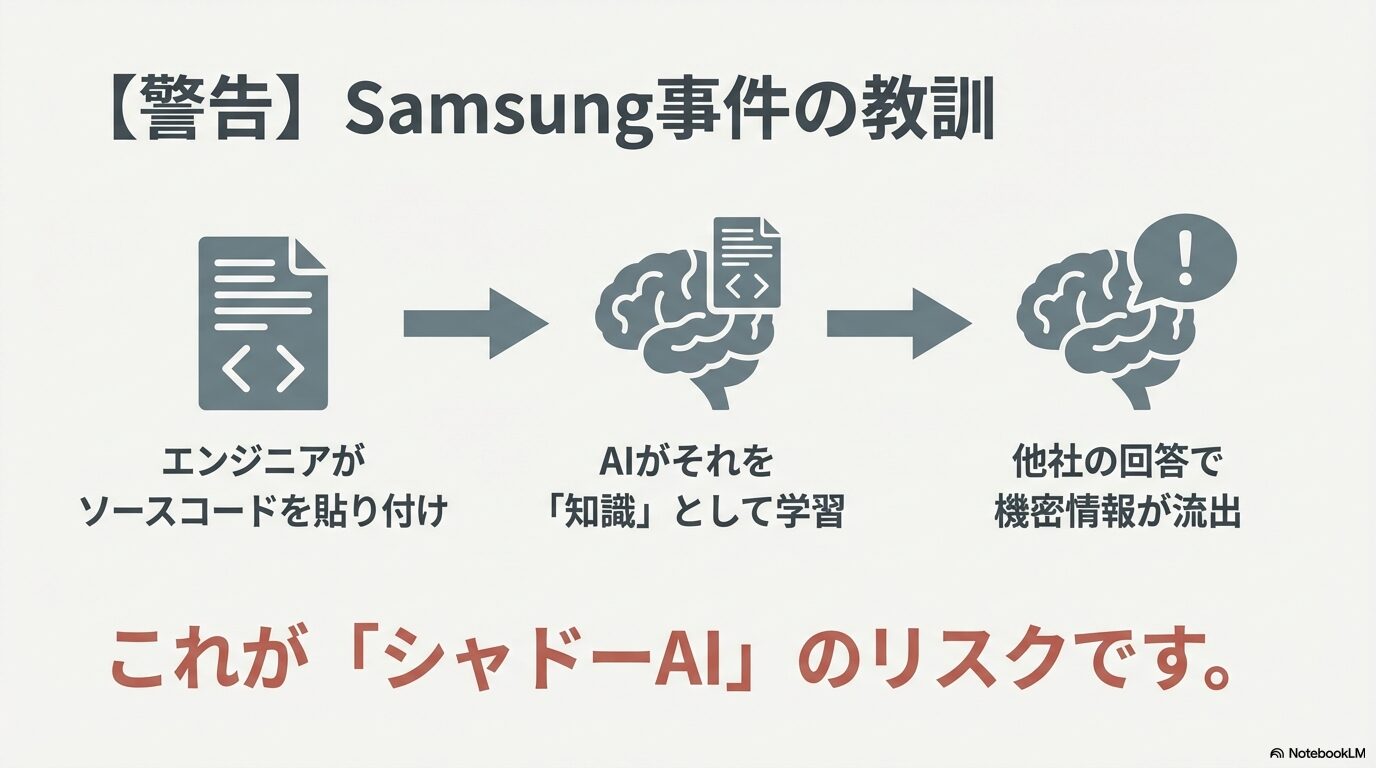
これがなぜ恐ろしいかというと、将来的に競合他社のエンジニアが「半導体の歩留まりを改善するコードを書いて」や「最新のスマホ戦略のトレンドは?」とAIに質問した際に、AIが学習した知識(=Samsungの機密情報)を元にした回答を生成してしまう可能性があるからです。これを「シャドー・リーク(Shadow Leak)」や「モデル反転攻撃」のリスクと呼びます。
この事件を受けて、Apple、Amazon、JPモルガンなど、世界の名だたる大企業が相次いで社内での生成AI利用を禁止、または厳格に制限する措置を取りました。これは企業だけの話ではありません。個人の日記や悩み相談が、いつの間にかAIの「常識」として他人に語られる未来を想像してみてください。私たちが「学習させない」設定にこだわるのは、こうした予期せぬ情報の拡散を防ぐためなのです。
履歴の自動削除設定を活用する
ここまで読んで、「学習されるのは絶対に嫌だ。でも、毎回履歴が消えてしまって、昨日の会話の続きもできないのはあまりにも不便すぎる…」と頭を抱えている方もいるかもしれません。プライバシーは守りたいけれど、利便性も捨てがたい。そんなジレンマに対する現実的な折衷案としておすすめなのが、「アクティビティの自動削除」設定です。
Googleのアクティビティ管理画面には、履歴を完全にオフにするだけでなく、一定期間が経過したデータを自動的にサーバーから消去する機能が備わっています。デフォルトの設定では「18ヶ月」になっていることが多いですが、これをユーザー自身で「3ヶ月」「18ヶ月」「36ヶ月」の中から選択変更することが可能です。
おすすめの設定は、最短期間である「3ヶ月」への変更です。これを選択しておけば、直近3ヶ月以内のチャット履歴は保持されるため、少し前の会話を振り返ったり、進行中のプロジェクトの文脈を維持したりすることは可能です。そして、3ヶ月が経過するとデータは自動的に消去され、永久にサーバーに残ることを防げます。
自動削除と手動削除の違い
| 機能 | 手動削除 (履歴オフ) | 自動削除 (3ヶ月) |
|---|---|---|
| 履歴の閲覧 | 不可 (ブラウザを閉じると終了) | 可能 (3ヶ月間は遡れる) |
| 学習リスク | 極めて低い (72時間保持のみ) | 中程度 (保存期間中は学習対象になり得る) |
| 拡張機能 | 利用不可 | 利用可能 |
ただし、注意していただきたいのは、この「3ヶ月間」に関してはデータがサーバーに存在するため、その間にGoogleのサンプリング(抽出)対象となり、人間のレビュアーによるチェックや学習プロセスに回る可能性は完全に排除できないという点です。あくまで「数年後にデータが亡霊のように出てくるリスク」を減らすための設定であり、即時的な学習防止策としては「アクティビティのオフ」には劣ります。ご自身が扱う情報の機密レベルに合わせて、最適な設定を選んでみてください。
業務でGeminiに学習させない運用法
ここからは視点を変えて、ビジネスシーンでの利用に焦点を当てます。もしあなたが「職場のPCで自分のGoogleアカウントを使ってGeminiに仕事の相談をしている」としたら、それは今すぐ見直すべき危険な行為かもしれません。企業組織としてどうデータを守るべきか、詳しく見ていきましょう。
仕事で使うなら無料版の業務利用はNG
結論から申し上げますと、会社の許可なく、あるいは明確なセキュリティルールのないまま無料版のGemini(個人のGmailアカウント)を業務で利用することは、コンプライアンス上「禁止」と同義だと考えてください。
なぜここまで強く言うのかというと、無料版のGeminiの利用規約(Terms of Service)において、ユーザーからの入力データは、Googleの製品やサービスの改善、つまり「AIモデルの学習」に利用されることへの同意が含まれているからです。「ちょっと文章を直すだけなら大丈夫だろう」「翻訳するだけだから」と思って、顧客からのメールの下書きや、会議の議事録、あるいは社内のプレゼン資料の内容を入力してしまうと、その瞬間に機密情報がGoogleのサーバーへ渡り、学習データとしてプールされるリスクが発生します。
これは、いわゆる「シャドーAI(Shadow AI)」と呼ばれる問題です。従業員に悪意はなく、むしろ「業務効率を上げたい」「良い成果を出したい」というポジティブな動機で行われるため、発見が難しく、企業にとっては非常に厄介なセキュリティホールとなります。Samsungの事例もまさにこのシャドーAIが引き起こした事故でした。
業務で生成AIを使うのであれば、「個人の判断で無料版を使う」のではなく、会社として正式に導入された「学習されない環境」を利用することが大原則です。もし会社にそのような環境がない場合は、上司やIT部門に相談し、安全なツールを整備してもらうよう働きかけるのが、あなた自身を守ることに繋がります。
有料版は学習しないという誤解
ここでよくある勘違いとして、「無料版は学習されるけど、月額料金を払っている有料版の『Gemini Advanced』なら、お客様扱いだから学習されないだろう」という思い込みがあります。しかし、これも個人のGoogleアカウント(Google One契約)で利用している場合は、大きな落とし穴があります。
個人の有料プランであるGemini Advancedは、あくまで「より高性能なAIモデル(Gemini Ultraなど)が使える」「大容量のストレージが付いてくる」といった機能面でのアップグレードプランであり、データプライバシーの扱いに関しては、基本的には無料版と同じポリシーが適用されるケースが多いのです。つまり、デフォルトの設定ではデータの改善利用(学習)が有効になっている可能性が高いということです。
「有料だから安全」と盲信するのではなく、ご自身が契約しているプランが「コンシューマー向け(個人向け)」なのか、それとも次項で解説する「エンタープライズ向け(法人向け)」なのかを明確に区別して理解する必要があります。もし個人版のAdvancedを業務で使っているなら、前述した「アクティビティ設定」をオフにしない限り、リスクは無料版と変わりません。

Gemini API無料版の学習リスク
エンジニアや開発者の方、あるいは社内のDX推進担当者の方も要注意です。自社で独自のAIツールを開発するためにGemini APIを利用する場合、「API経由なら学習されない」という通説は半分正解で半分間違いです。Gemini APIには「無料枠(Free Tier)」と「有料枠(Paid Tier)」の2種類が存在し、この2つではデータの扱いが天と地ほど違います。
| 項目 | 無料枠 (Free Tier) | 有料枠 (Paid Tier) |
|---|---|---|
| 学習への利用 | あり(Googleの製品改善に利用される) | なし(デフォルトで学習に利用されない) |
| データの保存 | 調整・改善のために保存・閲覧される可能性がある | 学習目的での保存は行われない |
| 推奨される用途 | 個人的な実験、プロトタイプ作成、非公開の検証 | 商用アプリケーション、本番環境、社内ツール |
多くの開発者が陥るのが、Google Cloudのプロジェクトを作成し、APIキーを発行しただけの状態で開発を進めてしまうパターンです。この状態だと自動的に「無料枠」が適用されることが多く、テスト送信した機密性の高いプロンプトや顧客データが、そのままGoogleの学習データとして吸い上げられてしまいます。
これを防ぐためには、Google Cloudコンソールで必ず「請求先アカウント(Billing Account)」を紐付け、明示的に有料プラン(従量課金)へ移行する必要があります。たとえ利用量が少なく、実際の請求額が0円だったとしても、「有料アカウント」としてのステータスを持っているかどうかが、データ保護の分かれ道となります。また、CLIツールなどを使用する場合は、設定ファイル(.gemini/settings.jsonなど)で統計情報の送信をオフにする設定もありますが、API自体の契約形態が最優先事項であることを忘れないでください。
Google Workspaceでの学習対策
では、企業が組織として安全にGeminiを導入し、従業員に使わせるにはどうすればいいのでしょうか。現在の最適解の一つは、「Gemini for Google Workspace」という法人向けアドオン契約を利用することです。
このサービスは、普段会社で使っているGmailやGoogleドライブ、ドキュメントなどと同じく、堅牢なエンタープライズセキュリティの基盤上で動作します。ここで最も重要なのが、「顧客データは顧客のもの(Your data is your data)」というGoogle Workspaceの基本原則が適用される点です。
具体的には、ユーザーが入力したプロンプト、AIが生成した回答、参照させた社内ドキュメントの内容などは、Googleの基盤モデルのトレーニングには一切使用されません。あなたの会社のデータを使って、GoogleのAIが賢くなることはないのです。また、企業ごとのデータは論理的に厳格に隔離されており、他社のデータと混ざることもありません。
「うちの会社はGoogle Workspaceを使っているから大丈夫だろう」と思っている方も、管理者が明示的にGeminiのライセンスを購入し、適切な設定を行っているか確認してみてください。無料の個人アカウントとは全く異なる、安全な「サンクチュアリ(聖域)」としてのAI環境がそこには用意されています。

法人契約とEnterpriseの安全性
さらに、金融機関や医療機関、官公庁など、極めて高いセキュリティ要件が求められる組織向けには、管理者による高度な統制機能が用意されています。
例えば、Google Adminコンソール(管理画面)を使えば、組織部門(OU)ごとにGeminiの利用許可を細かく制御できます。「研究開発部門にはAIを開放するが、アルバイトスタッフのアカウントでは使用禁止にする」といった運用が可能です。また、DLP(データ損失防止)機能と連携させることで、チャット入力欄に「マイナンバー」や「クレジットカード番号」、「社外秘」といった特定のキーワードが含まれていた場合、送信をブロックしたり、警告を表示したりすることもできます。
究極の対策:クライアントサイド暗号化(CSE)
「Googleのことさえ信用できない」という徹底したゼロトラスト環境が必要な場合、「クライアントサイド暗号化(CSE)」というオプションが切り札になります。これは、データがPC(ブラウザ)から送信される前に、企業自身が管理する暗号鍵で暗号化してしまう技術です。これを使えば、Googleのサーバーには暗号化された意味不明なデータしか届かないため、Googleの社員であっても、AIであっても、その中身を見ることは物理的に不可能になります。
ここまで徹底すれば、セキュリティリスクは限りなくゼロに近づきます。導入コストや運用ハードルは上がりますが、企業秘密を守るための「保険」としては決して高くない投資と言えるでしょう。
徹底してGeminiに学習させないために
今回は「Gemini 学習させない」というテーマで、個人の設定から企業のセキュリティ対策まで、かなり踏み込んで解説してきました。長文にお付き合いいただきありがとうございます。
AIは私たちの能力を拡張してくれる素晴らしいツールですが、その裏側でデータがどのように流れ、処理されているかを知ることは、デジタル社会を生きる私たちにとって必須の教養となりつつあります。「ただ便利だから」と無防備に使うのではなく、「どこまでなら情報を渡していいか」「ここからは守るべきラインだ」という境界線を、ユーザー自身がコントロールできるようになることが大切です。

個人の場合は「アクティビティをオフ」にして履歴を残さない運用を基本とし、どうしても履歴が必要な場合はリスクを理解した上で期間を短く設定すること。業務利用の場合は、安易な「野良AI(シャドーAI)」の利用を避け、会社が用意した安全な環境(Workspace版など)を利用すること。この2点を徹底するだけでも、情報漏洩のリスクは劇的に低減できます。
技術は日々進化し、Googleの規約や設定画面も変わっていくでしょう。しかし、「自分のデータは自分で守る」という意識さえ持っていれば、どんな変化にも対応できるはずです。正しい知識と設定で、安心してAIとの共存を楽しんでくださいね。

※本記事の情報は2026年時点のものであり、Googleの仕様変更などにより設定手順や名称が変わる可能性があります。正確な最新情報は必ずGoogleの公式サイトをご確認ください。