
こんにちは。AI index、運営者の「りょう」です。
いつも通り使っているのに、なぜかChatGPTのメモリが保存されないと悩んでいませんか。設定を変えたり指示を出したりしても反映されず、どうすればいいか迷ってしまうこともありますよね。実は多くの方が、突然メモリがいっぱいですと表示されるエラーや、保存されない原因と解決策について日々検索しているんです。正しい削除方法や裏側の仕様を少し知るだけで、このもどかしい問題は意外とすんなり解消するかもしれません。

- メモリ機能における保存容量やプラン制限の仕組み
- 保存エラーを引き起こすシステム裏側の不具合
- 不要なメモリを完全にリセットする正しい削除手順
- エラーを未然に防ぎスムーズに記憶させる運用テクニック
目次
ChatGPTのメモリが保存されない原因
ここでは、システム側で設定を記憶してくれない根本的な理由について詳しく見ていきましょう。容量の制限や見落としがちな仕様、そして現在報告されているバグなど、いくつかの要素が絡み合っていることが多いんです。システムがどのような基準で情報を弾いているのか、その裏側を知ることが解決への第一歩となります。
メモリがいっぱいですという警告の理由
目に見えない保存領域の枯渇
システムを使っていると突然表示される「メモリがいっぱいです」という警告ですが、この直接的な理由は保存領域の物理的な枯渇にあります。多くの方が「AIは無限に情報を覚えてくれる」と期待しがちですが、実際にはアカウントごとに厳格なデータ保存上限が設けられているんですね。AIの記憶領域は無限のクラウドストレージではなく、例えるなら「小さな引き出し」のようなものです。様々な前提条件やルールを詰め込みすぎると、あっという間にこの引き出しが満杯になり、システムは新しい情報を受け付けてくれなくなってしまいます。
コンテキストウィンドウとの違い

ここでよくある誤解が、「1回の会話で読み込める文字数(コンテキストウィンドウ)」と「永続的な記憶(メモリ)」を混同してしまうことです。コンテキストウィンドウが数万トークンから数十万トークンという広大な作業スペース(大きなデスク)であるのに対し、メモリ機能はそこから数千トークンだけを切り取った専用の保管庫(鍵付きの小さな引き出し)になります。この2つはシステム上完全に独立しています。
そのため、「まだまだ長い文章を読み込めるはずなのに、なぜ設定を保存してくれないの?」という疑問が生まれますが、それは単に「デスクは空いているけれど、引き出しの容量がいっぱいになってしまった」という状態なのです。日常的にプロンプトの指示や個人の嗜好を細かく記憶させているヘビーユーザーほど、この目に見えない上限に早く到達してしまい、エラーに直面しやすくなります。
※ここで紹介する数値データや仕様はあくまで一般的な目安です。AIのアップデートにより頻繁に変更されるため、正確な情報は公式サイトをご確認ください。
プランごとの容量制限と自動管理の有無
無料プランと有料プランの決定的な差

それでは、現在提供されているプランによって、どれくらい容量や機能に違いがあるのかを見てみましょう。実は、無料版や新しいGoプランと、有料のPlus・Proプランの間には、目に見えない大きなアーキテクチャの差が存在しています。
| プラン名 | メモリ容量の目安 | 自動メモリ管理機能 |
|---|---|---|
| Free(無料版) | 約2,000トークン | なし(手動管理) |
| ChatGPT Go | 約8,000トークン | なし(手動管理) |
| ChatGPT Plus | 約8,000トークン | あり(Web版のみ) |
| ChatGPT Pro | 約8,000トークン以上 | あり(Web版のみ) |
調査やコミュニティの報告を総合すると、無料プラン(Free)のユーザーに割り当てられているメモリ領域は約2,000トークン程度(英語テキストで数ページ分)と非常に限定的です。一方、Go、Plus、Proなどの有料プランになると、この領域が約8,000トークンへと大幅に拡張されます。しかし、容量の多さ以上に重要なのがシステムによる「管理機能」の違いです。
自動メモリ管理機能(Automatic Memory Management)とは
表の中で最も注目したいのが、Plusプラン以上のWeb版ユーザーにのみ提供されている自動メモリ管理機能の有無です。PlusやProプランでは、メモリの容量がいっぱいになりそうな時に、AIが最近の話題の頻度や重要度を自律的に評価します。そして、昔のあまり使っていない記憶を自動的に「お休み状態(背景化)」にしてくれるのです。(出典:OpenAI公式ブログ『Memory and new controls for ChatGPT』)
背景化されたメモリは削除されたわけではなく、設定画面でグレーアウトして残りますが、普段の会話のコンテキストからは除外されるため、エラーを出さずに新しい情報を保存し続けることができます。一方、FreeやGoプランにはこの機能がないため、限られた上限に達すると即座にエラーが吐き出され、ユーザー自身が手動で不要な記憶を削除しなければならないという運用の負担が発生するわけです。
履歴削除で消えない仕様と勘違いの原因
2つの独立した記憶システム

「過去のチャット履歴を全削除したのに、まだ以前の変な設定を引きずっている!」と驚いたことはありませんか?実は、ChatGPTの記憶システムは単一のデータベースではなく、大きく分けて2つの独立したレイヤーによって構成されているんです。ここを理解していないことが、トラブルシューティングを困難にする最大の原因となっています。
1つ目のレイヤーは「チャット履歴の参照」です。これは会話の流れ全体からAIが文脈を読み取り、ユーザーの興味や傾向を学習する機能です。特定のプログラミング言語について長く話していれば、別の会話でもその言語を提案しやすくなる、といった具合ですね。これには明確な保存上限はありませんが、設定をオフにするとサーバーから学習データが破棄されます。
bioツールによる永続的なメタデータ
2つ目のレイヤーが、皆さんが直面している問題の核心である「保存されたメモリ」です。ユーザーが「私がベジタリアンであることを覚えておいて」と明示的に指示したり、AIが重要だと判断して抽出した具体的な事実は、内部的にbioツールと呼ばれる裏側の仕組みを使って、専用のメタデータとしてガッチリと書き込まれます。システムは新しいチャットを始めるたびに、このメタデータを裏側のシステムプロンプトとして強制的に読み込みます。
注意したいポイント:左側のサイドバーからチャットのログ(履歴)をいくら削除しても、この第2のレイヤーである「保存されたメモリ(bioツールで書き込まれたもの)」は一切消去されません。情報を完全に消去するには、設定画面の「メモリの管理」から該当項目を直接削除しなければならないのです。この構造的な違いを知っておくことが非常に重要です。
データ重複などバックエンドのバグ問題
内部エラーによるデータの複製現象
ストレージ容量が十分に余っているはずなのに、画面上では「メモリを更新しました」と表示されるのに、実際に設定画面を確認すると何も保存されていない、という厄介なケースも多数報告されています。これはユーザー側のミスではなく、サーバーの裏側(バックエンド)で発生しているバグが影響している可能性が高いんです。
開発者コミュニティなどの報告を追っていくと、AIが新しい情報を保存しようとする際、システムが誤作動を起こして全く関係のない過去のデータを上書きしてしまったりする現象が確認されています。ひどいケースになると、ユーザーが1回「これを保存して」と指示しただけなのに、既存の特定のエントリが11回も重複して複製され、一気にメモリ容量を食いつぶしてしまうという事態も発生しています。また、過去の会話に全く存在しない架空の事実(ハルシネーション)を勝手にメモリに追加してしまうバグも見受けられます。
マークダウン形式が引き起こす保存停止
さらに有力視されている原因の一つが、「データ形式の破損」による保存プロセスのサイレントな停止です。多くのユーザーは、自分の好みやプロンプトのルールを綺麗に整理するため、箇条書きのリスト(- や *)、太字(**)、過度な改行といった「マークダウン記法」を多用してAIに送信します。
しかし、複雑な装飾が含まれたテキストブロックを保存しようとすると、バックエンドのパース処理(データを読み解く処理)が失敗しやすくなります。その結果、AIは「わかりました」と返事をしても、実際にはデータが破損して保存プロセスが途中で強制終了してしまうのです。エラーメッセージが出ないため、ユーザーは保存されたと思い込み、後になって「指示を無視された!」と感じることになります。
長文入力時の保存制限とエラーの仕組み
長文テキストに対するシステム側のブロック
もうひとつ非常に頻繁に見られる原因が、ユーザーが一度に保存しようとする情報量(文字数やブロックサイズ)の制限に引っかかっているケースです。ChatGPTの永続メモリ機能は、本来「ユーザーの高次的な嗜好、職業、簡単なルール」などを記録するために設計されています。そのため、長大な世界観の設定や、完全なプロンプトのテンプレートを逐語的(一言一句そのまま)に保存することには全く適していません。
現在のシステム仕様では、数百語におよぶ長文を一度にメモリに押し込もうとすると、AIはエラーメッセージすら出さずにその保存要求をスルー(無視)する挙動が確認されています。ユーザーにとっては「ルールを投げ込んだのに覚えてくれない」という致命的な不具合に見えますが、システム側からすれば「一度に処理できる情報量のキャパシティを超えているため安全に破棄した」という扱いになっているのです。
コンテキスト・ドリフト(会話の漂流)現象
また、「保存したはずの情報をAIが忘れてしまう」という事象は、メモリへの書き込み失敗だけでなく、単一の長い会話の中で起こる「コンテキスト・ドリフト」によっても引き起こされます。AIは数万トークン以上の文脈を保持できますが、同じチャット画面の中で話題が4回、5回と頻繁に変わっていくと、内部の注意機構(アテンション)が焦点を失ってしまいます。
最新のAI研究では「ホワイトボードのメタファー」と呼ばれたりしますが、情報が蓄積されて処理上限の半分を超えたあたりから、AIの情報の検索・参照能力が急激に低下する「Lost in the Middle(中間情報の喪失)」という弱点が顕在化します。実際にはメモリに保存されていても、直近の膨大な会話のノイズに埋もれてしまい、AIの推論から除外されてしまうんですね。これも「保存されない」と錯覚してしまう大きな要因です。
ChatGPTのメモリが保存されない解決策
原因や裏側のバグの仕組みがわかったところで、次は具体的な対処法とトラブルシューティングについて解説していきますね。単純な手動削除の手順から、エラーを回避するためのプロンプトの出し方、そして新しい機能を活用した高度な運用術まで、すぐに試せる実践的な方法をまとめました。
確実な不要メモリの削除方法と基本手順
設定画面からの明示的なパージ(消去)
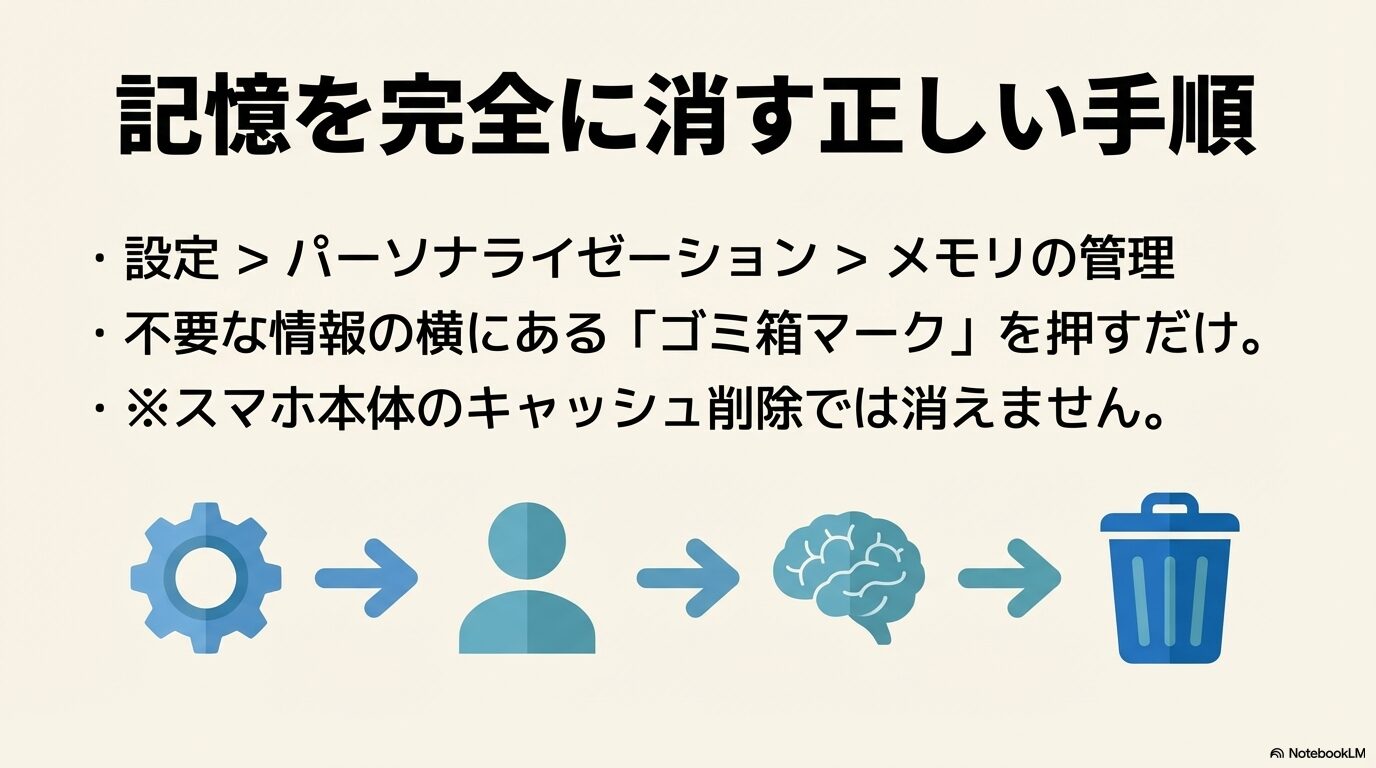
容量がいっぱいになってしまった場合や、間違った設定をAIが覚えてしまった場合、左側のチャット履歴をいくら削除しても問題は一切解決しません。専用のストレージを解放するためには、設定画面から明示的な削除(パージ)を行う必要があります。パソコンのブラウザ版を使用している場合の手順は以下の通りです。
- 画面左下にある自分のユーザープロファイルアイコンをクリックし、「設定(Settings)」を開く
- 左側のメニューから「パーソナライゼーション(Personalization)」のタブを選択する
- 「メモリの管理(Manage Memory)」というボタンをクリックする
- これまで記憶されたリストが時系列で表示されるので、不要な情報の右側にある「ゴミ箱アイコン」をクリックして消去する
もし、これまでの記憶を完全にゼロにして真っ新な状態から始めたい場合は、「すべてのメモリを削除する(Clear ChatGPT’s memory)」を選択することで一括リセットが可能です。
スマートフォンアプリでの注意点
iOSやAndroidのスマートフォンアプリ版を使用している場合も、基本の構造は全く同じです。サイドメニューから設定を開き、パーソナライゼーションへと進んでメモリの管理から削除を行います。ここで非常に多い勘違いが、スマホ本体の設定画面(iOSの設定アプリなど)から「ChatGPTアプリのキャッシュ削除」を行ってしまうことです。キャッシュの削除はアプリの動作を軽くするための一時ファイルの消去であり、AIのクラウド上に保存されたパーソナライズ記憶(メモリ)を消すものではありません。必ずアプリ内のアカウント設定から操作を行ってくださいね。また、会話の中で直接「先ほどの〇〇についての記憶は消して」と指示して、その場で消去させることも可能です。
保存エラーを回避するプロンプトのコツ
バックエンドツールを強制起動させる指示
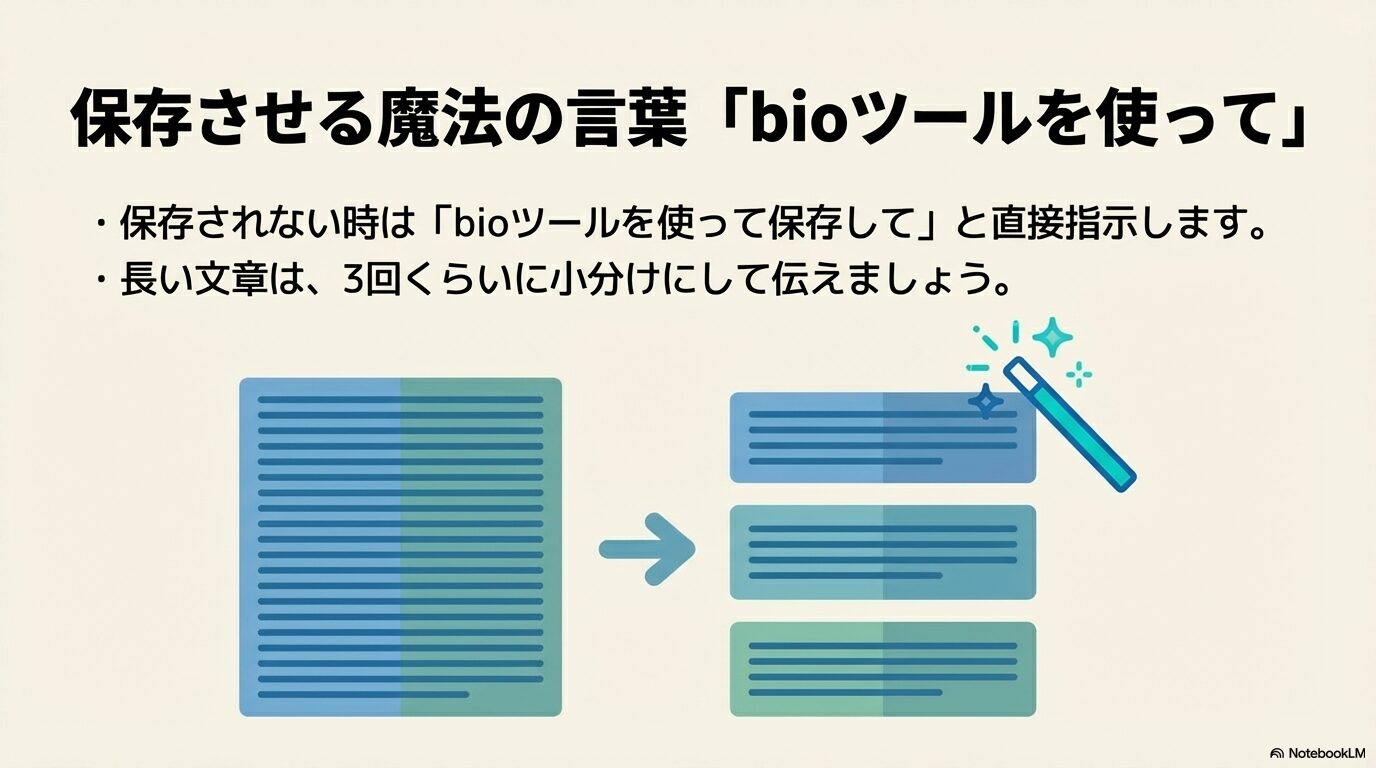
システムが「メモリに保存しました」と返答したのに、実際には管理画面に反映されていないバグに遭遇した場合、システムの書き込みプロセスを強制的に動かすための少し特殊なプロンプト(指示の出し方)が必要になります。
単に「これを覚えておいて」と伝えるのではなく、AIの裏側で動いている仕組みを直接指定します。「この情報を保存してください。永続メモリに追加するために、内部の bio ツールを明示的に使用して実行してください」と指示を出してみてください。こうすることで、AIが自律的な判断で保存をスルーするのを防ぎ、強制的に書き込み処理(トリガー)を引かせることができるケースが多く報告されています。
分割保存(Chunking)と圧縮(Consolidation)
長文が弾かれてしまう問題に対する最も有効なアプローチは、情報の細分化です。長いルールを一度に投げるのではなく、意味のまとまりごとに3回〜4回に分け、「まずこの第一部分だけをメモリに保存し、完了したら教えてください」と対話形式で小出しに記録させる(チャンク分割)手法を取りましょう。
さらに、容量上限の警告が出たけれど過去の情報を消したくない場合の高度なテクニックとして、「メモリの圧縮統合(Consolidation)」があります。AIに対して「現在のメモリにある、私のコーディングに関する3つの別々の記憶を読み込み、重複を省いて1つの短い文章に統合して保存し直して」と指示します。これにより、複数のトークン消費枠をキュッと1つにまとめ、物理的な空き容量を強制的に作り出すことができるんです。
設定の切り替えと新規チャットでの対策
チャット履歴参照のトグルリセット
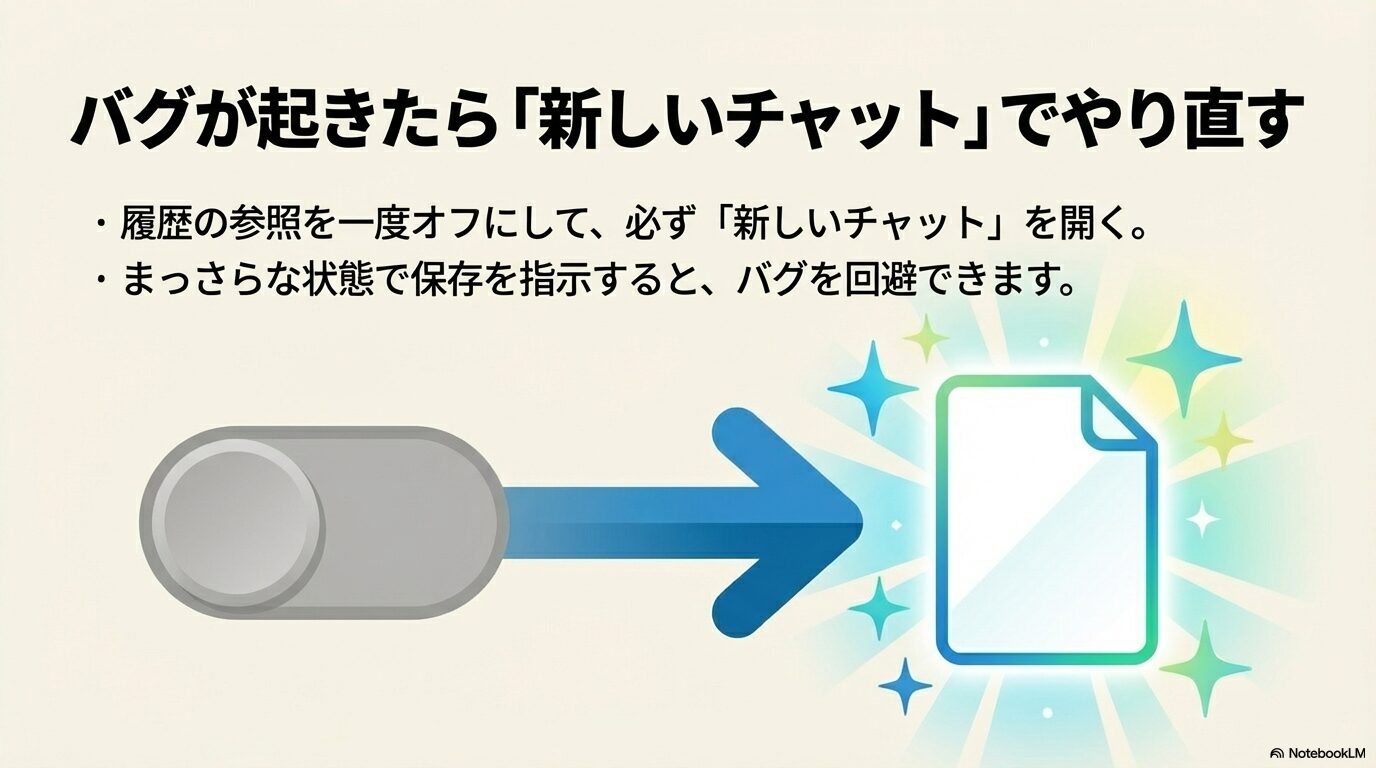
システムが過去のメモリのループに陥ってしまい、何度指示しても古い情報を上書きできない、あるいは保存自体が全く機能しなくなった場合は、一度システムを意図的にリフレッシュする迂回策が効果的です。
まず、設定画面のパーソナライゼーションから「チャット履歴の参照(Reference chat history)」のスイッチを一度「オフ」にします。そしてここからが重要ですが、必ず新しいチャット(New Chat)を立ち上げてください。その真っ新なセッションにおいて、改めて情報の保存を指示します。正常にメモリ管理画面に保存されたことを確認した後、再び設定を「オン」に戻すという手順を踏みます。今開いている既存のチャット内で設定を切り替えても、裏側に古いコンテキストが残存しているためバグが継続することが多く、新しいセッションの立ち上げが不可欠なんですね。
ハンドオフ・プロセスによる文脈の引き継ぎ
長時間のチャットでAIがメモリを忘れてしまうコンテキスト疲労を防ぐには、「ハンドオフ(引き継ぎ)」という手法がベストプラクティスです。話題が何度か変わったり、AIが指示を無視し始めたなと感じたら、「ここまでの議論の要点、現在の成果物、初期の前提条件をまとめた、引継ぎ用のマークダウン文書を作成して」と指示します。生成された要約をコピーし、完全に新しいチャットにペーストして再開することで、AIの頭の中(ホワイトボード)が綺麗にリセットされ、メモリの参照能力と推論精度が最高水準に回復しますよ。
プロジェクトや独自GPTsの使い分け
用途に応じた三層構造のアプローチ
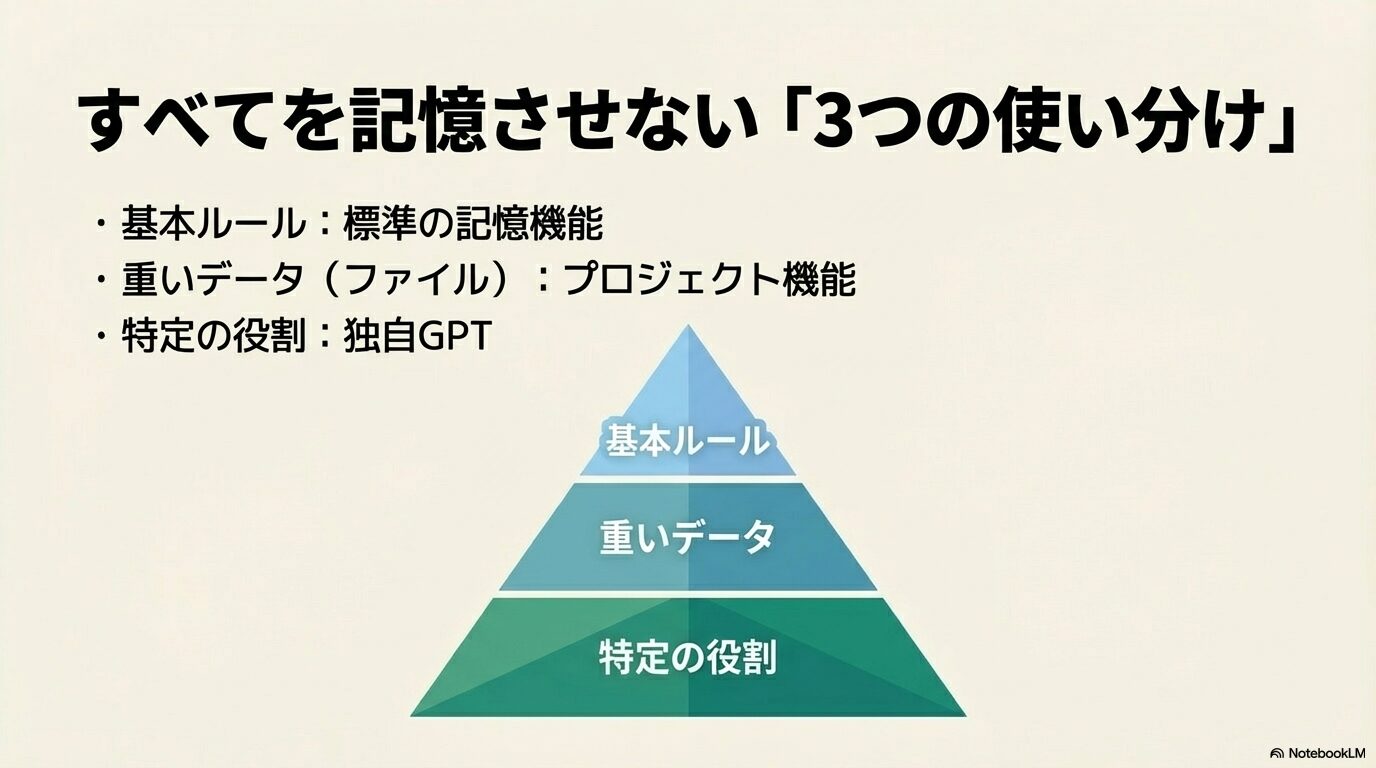
ChatGPTのメモリ機能が持つ根本的な容量制限(数千トークン)や、バグによる保存不具合のリスクを考えると、高度な業務利用において「すべての前提条件を標準のメモリ機能だけで管理する」という運用は非常に脆弱だと言わざるを得ません。本当にAIを使いこなすためには、メモリ機能の限界を補完する代替の機能と使い分けることが不可欠です。
おすすめのアーキテクチャ使い分け:
- 標準メモリ機能:「私はエンジニアである」「常に結論から簡潔に答えて」といった、アカウント全体で共通する普遍的なルール。
- Projects(プロジェクト)機能:特定のクライアントの文体ガイドラインや、公式ドキュメントなどの局所的で大容量のデータ(ファイルとしてアップロード)。
- Custom GPTs(独自GPT):「SEO記事の専属校正者」「法務文書チェッカー」など、特定の役割(ペルソナ)に特化させた固定の環境。
汎用的なものは標準メモリに任せ、重たいデータはProjectsという隔離されたワークスペースに投げ込み、特定の役割はCustom GPTsとして独立させる。この三層構造を意識することで、情報が混ざり合って崩壊するリスクを劇的に減らすことができます。
CAG技術など外部処理への委譲
さらに大規模なデータ、例えば数十万文字に及ぶ社内マニュアルなどを記憶させたい場合は、ChatGPTの単純なメモリ機能では太刀打ちできません。こういったケースでは、情報をテキストファイルやCSVにまとめ、コードインタープリター(Advanced Data Analysis)を用いたデータ分析機能に処理を委譲するか、外部のRAG(検索拡張生成)やCAG(キャッシュ拡張生成)といった専用のデータベースシステムに移行していくのが、確実かつプロフェッショナルなアプローチになります。適材適所でツールを選ぶ視点が大切ですね。
一時的なチャットでノイズ蓄積を防ぐ
「Temporary Chat」の常用による予防

不具合に直面してから対処するのではなく、メモリが破損したり満杯になったりするのを未然に防ぐための「予防的運用」を日常のワークフローに組み込むことが、AIを快適に使いこなすための最大の鍵となります。
一度きりの調べ物、一時的なプログラムコードのデバッグ、ちょっとした翻訳作業など、将来の会話に影響を与えたくない対話を行う際は、必ず画面上部のメニューから「一時的なチャット(Temporary Chat)」モードを選択する習慣をつけてみてください。このモードでは、既存のメモリが参照されないだけでなく、会話の内容が新たなメモリとして抽出・保存されることも一切ありません。これにより、メモリ空間に無関係な情報が蓄積される「ノイズ」を劇的に減らすことができ、ストレージ容量の無駄遣いを未然に防ぐことが可能になります。
機密情報と動的データの入力回避
もう一つの予防策として、頻繁に変化する動的なデータや、機密情報をメモリに覚えさせないという規律も重要です。システムは健康情報などの機密データを自発的に記憶しないよう訓練されていますが、ユーザーが明示的に「保存して」と指示した場合は処理されてしまいます。
クレジットカード番号や住所といった個人情報はもちろん、「今週のスケジュール」「明日の天気」のようなすぐに陳腐化するデータを保存させることは、セキュリティ上のリスクとなるだけでなく、貴重なメモリ容量の完全な無駄遣いとなってしまいます。メモリ機能はあくまで「変化しにくい普遍的な嗜好やビジネスの基本ルール」の保管庫として厳密に定義し、定期的に設定画面から「大掃除」を行うことで、クリーンな状態を保つように心がけましょう。
結論:ChatGPTのメモリが保存されない時
制約を理解し戦略的に統制する
いかがでしたでしょうか。ChatGPT メモリ 保存されないという検索クエリの裏にある問題は、単なる一時的なソフトウェアのバグとして片付けることはできません。数千トークンという物理的な保存容量の限界、バックエンドでのデータ破損や重複バグ、そして長時間のセッションにおけるコンテキスト・ドリフトなど、システムのアーキテクチャそのものが抱える構造的な摩擦が原因となっています。
エラーが発生した際は、まずは設定画面から不要な記憶を明示的にパージし、bioツールの強制起動やチャンク分割といったプロンプトの工夫を試してみてください。それでもうまくいかない場合は、設定のトグルを切り替えて新しいチャットを立ち上げることで、大半のバグは回避できるはずです。
AIにすべての情報を漠然と記憶させるという過度な期待を捨て、標準メモリ、Projects機能、Custom GPTsを戦略的に使い分ける高度な運用スキルを身につけることが、これからのAIパートナーシップにおいて非常に重要になってきます。一時的なチャットモードなども活用しながら、システムを自分の統制下に置いて快適に使いこなしていきましょう。
※本記事で紹介した機能や仕様、データの取り扱いルールについては、今後のアップデートで変更される可能性があります。最終的な判断や業務での本格的な運用については、必ず専門家にご相談いただくか、公式の最新ドキュメントをご確認ください。これからも、皆さんの疑問解決に役立つ情報を発信していきます!