
こんにちは。AI index、運営者の「りょう」です。
最近、AIを活用して日々の業務を効率化する人が増えていますが、せっかく生成したデータを手元に保存しようとした際に、ChatGPTでファイルがダウンロードできないという壁にぶつかってしまうことはありませんか。
例えば、仕事で使うためのPDFやエクセルの資料を作成したのに、いざ保存しようとするとエラーが出てしまったり、iPhoneやAndroidのスマートフォンから操作しているときにどうしても取り出せなかったりと、原因がわからず困惑してしまうケースが後を絶ちません。また、新しく追加されたCanvas機能を使っている最中にファイルが消えてしまったり、特定のファイル名指定やBase64エンコードといった専門的な対処法が必要になるのかと不安に感じる方もいらっしゃるかもしれませんね。さらに、2026年最新制限などの影響でシステム自体がファイルの保存をブロックしている場合もあります。
この記事では、そのような問題に直面している皆さんのために、エラーの裏側で何が起きているのかを一つずつ紐解き、今すぐ試せる具体的な解決策を分かりやすくお伝えしていきます。少し複雑に見えるかもしれませんが、原因さえ分かれば案外すんなりと解決できることが多いので、ぜひ最後まで目を通してみてくださいね。
- ファイルのダウンロードを妨げる2026年の最新制限と仕様
- スマートフォンやブラウザ環境に潜むエラーの根本的な原因
- 日本語ファイル名や拡張子による文字化けや保存失敗の仕組み
- ファイルを確実に手元へ取り出すための実践的なトラブルシューティング
目次
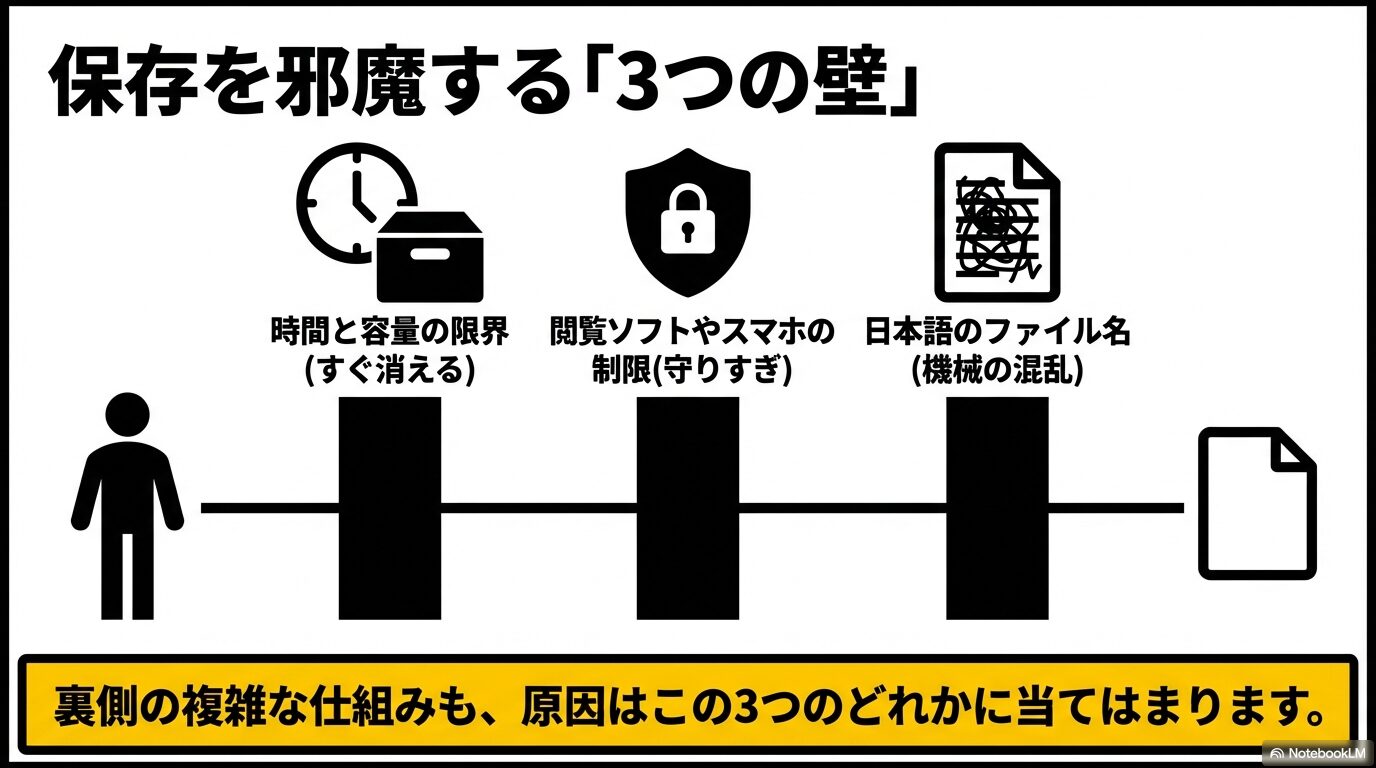
ChatGPTのファイルがダウンロードできない原因

バックエンドの複雑な仕組みや、私たちが普段使っているデバイスの設定など、ChatGPTでファイルがダウンロードできない原因は実に様々です。ここでは、なぜエラーが発生してしまうのか、その背景にある主な要因を6つの視点から詳しく解説していきますね。エラーの仕組みを理解することが、一番の近道かなと思います。
2026年最新制限による容量と頻度の上限
2026年に入り、OpenAIのシステムアーキテクチャやプランごとの利用制限は劇的な変化を遂げました。実は、ファイルの生成やダウンロードができない原因の多くが、この「見えない利用制限」に引っかかっているケースなんです。これまで主流だったモデルから、新たに「GPT-5.3 (Instant)」や「GPT-5.4 (Thinking / Pro)」といった最新モデルへの移行が進む中で、膨大な計算リソースを必要とするファイル処理に対しては、以前よりもはるかに厳格な上限(キャップ)が設けられるようになりました。
無料プランと有料プランにおけるファイル処理の格差
まず、最も影響を受けやすいのがファイルアップロードと生成(ダウンロード)の頻度制限です。有料プランである「ChatGPT Plus」や「Go」のユーザーであれば、「3時間あたり最大80ファイル」までの処理が許可されています。しかし、無料(Free)プランのユーザーに対する制限は非常に厳しく、「1日あたりわずか3ファイル」に設定されています。この無料枠を一度でも超過してしまうと、システムは新たなファイルの出力・ダウンロード要求を一切受け付けなくなり、画面上にはエラーが表示されるか、ボタンが反応しない状態に陥ります。さらに、システムの混雑状況(ピーク時間帯など)によっては、有料プランであってもこの上限が動的に引き下げられることがあるため、「昨日はダウンロードできたのに今日はできない」といった不安定な挙動を引き起こす原因となっています。
アカウント全体のストレージ容量(ハードリミット)の罠
注意:アカウントに蓄積された見えないデータ容量
ChatGPTのシステム全体には、個人ユーザーあたり10GB、組織アカウントあたり100GBという絶対的なストレージ容量上限が存在します。過去のチャットで生成した重い画像ファイルやエクセルデータが蓄積してこの制限に達していると、新しいファイルを生成するための領域が確保できず、ダウンロード処理の直前でエラーとなります。
意外と盲点なのがこのストレージ上限です。日々の業務で何気なくファイルを生成し続けていると、数ヶ月でこの10GBの制限に到達してしまうことがあります。この状態に陥ると、不要なチャット履歴やファイルを「設定画面」から手動で定期的に削除しない限り、一生新しいファイルをダウンロードすることができません。
モデル選択による計算リソースの不足とタイムアウト
また、複雑なデータ処理を伴うマクロ付きのエクセルファイルや、大量のグラフを描画した数百ページに及ぶPDFの生成を、日常タスク用の軽量モデル(GPT-5.3 Instantなど)で要求した場合、モデルの計算能力やコンテキスト維持能力を超えてしまい、生成の途中でプロセスがクラッシュ(タイムアウト)することがあります。その結果、フロントエンドの画面には「完了しました」と表示されてリンクが出現しても、中身が空っぽであったり、ダウンロードの途中で失敗したりする現象が起きます。確実に重いファイルを生成しダウンロードするためには、高度な推論能力を持つ「GPT-5.4 Thinking」モードなどを適切に選択してあげる必要があるんですね。
| プラン・機能カテゴリ | ファイル処理頻度の上限 | 最大容量(生成時) | アカウントストレージ上限 |
|---|---|---|---|
| Free(無料プラン) | 最大3ファイル / 1日 | 最大25MB | 10 GB |
| ChatGPT Plus / Go | 最大80ファイル / 3時間 | 最大25MB | 10 GB |
| Pro / Team / Business | 最大80ファイル / 3時間 | 最大25MB | 100 GB (組織全体) |
※本記事で紹介している制限の数値データや仕様はあくまで一般的な目安であり、今後のアップデートで変更される可能性があります。正確な情報はOpenAIの公式サイトをご確認ください。
バックエンドの揮発性と一時保存の制約
ChatGPTが生成したファイルは、一般的なWebサイトの画像やPDFのように、固定されたサーバーの住所(URL)にずっと保存されているわけではありません。ここを誤解していると、「さっきまでダウンロードできたのになぜ?」とパニックになってしまいます。ファイルのダウンロード障害の最も根本的かつ構造的な原因は、このプラットフォームが持つ「揮発性(エフェメラル性)」という特殊なシステム設計にあります。
セッションに紐づく仮想サンドボックスの仕組み
ユーザーがChatGPT上でファイルの生成を要求した際、バックエンドではPython環境などが稼働し、各チャットセッションに紐づく一時的な「仮想領域(サンドボックス)」が構築されます。生成されたファイルは、この一時マウント領域にのみ格納されます。なぜこのような面倒な仕組みを採用しているかというと、世界中の何億人というユーザーの膨大なデータを安全に隔離し、他のユーザーに情報が漏洩するのを防ぐプライバシー保護の観点と、無限に増え続けるファイルによってサーバーのハードディスクがパンクするのを防ぐための、不可欠なセキュリティ要件だからです。
「File Not Found」を引き起こす極端に短い有効期限
リンク切れが起きる具体的なタイミング
生成されたファイルに対するダウンロードリンクは、おおむね15分から30分未満という極めて短い有効期限しか持っていません。時間が経過すると、バックエンドの「ガベージコレクション(不要データのお掃除機能)」が作動し、ファイルの実体がサーバーから完全に破棄されます。
この揮発的な特性こそが、ダウンロード失敗の主要なトリガーです。例えば、ユーザーが「ファイルが完成しました」というメッセージを確認した後、「とりあえずお昼ご飯を食べてから後でダウンロードしよう」と考え、数十分経過してからダウンロードボタンをクリックしたとします。この時、ブラウザの画面上にはまだ青いダウンロードリンクが存在していますが、裏側ではすでにファイルが消去されているため、システムは該当のリソースにアクセスできず「File Not Found(ファイルが見つかりません)」や「Failed to get upload status」という致命的なエラーを返します。

489バイトの謎の破損ファイルがダウンロードされる現象
さらに厄介なのが、タイムアウト後に無理やりダウンロードを試みると、本来のエクセルやPDFデータではなく、「489バイト」程度の極端に容量が小さい破損したシステムファイルが保存されてしまう事象です。これは、システムがエラー内容を記載した小さなテキストデータを、間違って目的の拡張子(.xlsxや.pdfなど)として出力してしまっている状態です。ファイルを開こうとしても「ファイル形式が無効です」と表示されるだけで、使い物になりません。ChatGPTでファイルを生成させた場合は、「生成完了のメッセージが出たら、数分以内に即座にダウンロードボタンを押してローカルに保存する」という鉄則を習慣づけることが、このトラブルを回避するための最善策となります。
ブラウザ拡張機能と通信経路の干渉
バックエンドのサーバー側でファイルが正常に作成され、ダウンロードリンクの有効期限内であったとしても、データがあなたのパソコンやスマホに届くまでの間には、見えない「通信の関門」がいくつも存在します。多くの方が「ChatGPT側のバグだ!」と思い込みがちですが、実はユーザー自身が使っているWebブラウザの環境や、ネットワークのセキュリティ設定が原因で、プロセスが強制的に遮断されているケースが後を絶ちません。
広告ブロッカーやトラッキング防止機能によるサイレントキル
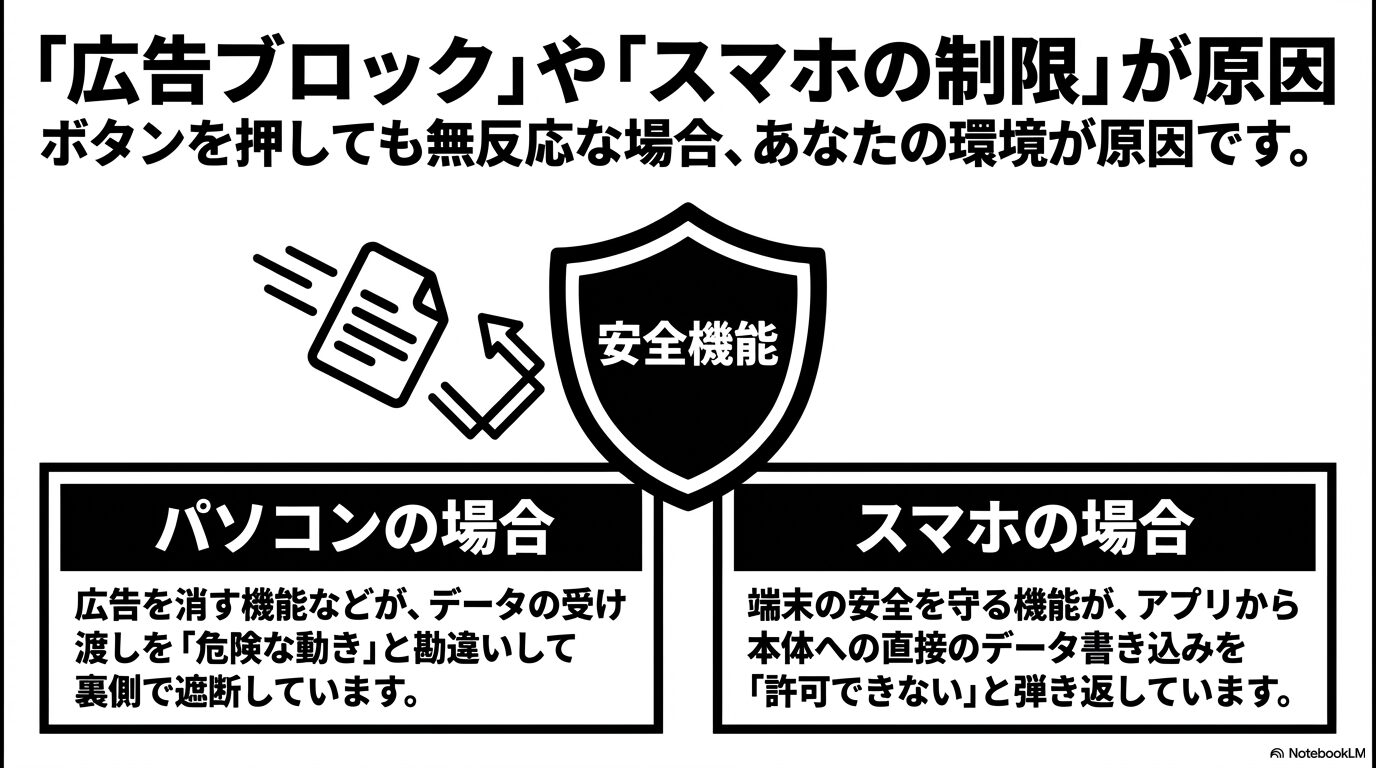
Google ChromeやMicrosoft Edge、Safariなどのモダンブラウザに、便利な「拡張機能(アドオン)」を入れている方は非常に多いと思います。特に、AdBlockやuBlock Originなどの強力な広告ブロッカー、あるいはPrivacy Badgerといったトラッキング防止ツールは、Webサイト上の怪しい動きを監視してブロックしてくれます。しかし、ChatGPTがファイルのダウンロードを開始する際、バックグラウンドで一時的な「Blob URL(sandbox:/形式など)」を動的に生成し、JavaScriptを使ってダウンロードイベントを強制的に発火させるという少し特殊な挙動をとります。
広告ブロッカーやセキュリティツールは、このChatGPTの正常なデータ受け渡しプログラムを、「ユーザーの意図しない悪質なポップアップ」や「不正なリダイレクト通信」と誤認してしまうことがあるんです。その結果、プログラムが裏側でパージ(消去)され、画面上にはエラーメッセージすら出ないまま、「ダウンロードボタンを何度クリックしても全く反応しない」という、非常に解決が難しい状態に陥ります。ボタンが無反応な場合は、まず間違いなくブラウザの拡張機能が干渉していると考えて良いでしょう。
企業ネットワークのファイアウォールと未知のURLスキーム
会社のパソコンでダウンロードできない理由
企業や医療機関、教育機関などの厳密に管理されたネットワーク環境下では、社内の情報漏洩を防ぐための強固なファイアウォールが設置されています。これらが、ChatGPTが利用する一時的な外部クラウドストレージドメインを「未承認サイト」として意図的に切断しているケースがあります。
さらに、仮想プライベートネットワーク(VPN)やプロキシサーバーを利用している場合も要注意です。OpenAI側には強力なWebアプリケーションファイアウォール(WAF)が導入されており、特定のVPNのIPアドレスから大量のリクエストが来ると、それを「ボットによる攻撃」や「スクレイピング行為」とみなして、通信の信頼性(IPレピュテーション)を低く評価します。テキストのチャット自体は軽くても、帯域幅を消費する重いファイルのダウンロード通信が始まった瞬間に「403 Forbidden(アクセス拒否)」というエラーを返し、通信を強制切断してしまう仕組みです。心当たりがある方は、スマートフォンのモバイル回線(4G/5G)に切り替えてテザリングで試してみると、あっさりダウンロードできることが多々あります。
iPhoneやAndroidでのアクセス権限
「パソコンからはダウンロードできるのに、スマホのアプリからだと絶対失敗する」とお悩みの方も多いのではないでしょうか。「ChatGPT ファイル ダウンロードできない iPhone」や「Android 権限設定」といった検索キーワードが絶えないのには、明確な理由があります。パソコンとスマートフォンでは、アプリがデバイスの中身(ファイルシステム)に触れる際の「思想」が根本的に異なっているからです。
モバイルOS特有の厳格なサンドボックス制約
iOS(iPhone/iPad)およびAndroidプラットフォームにおいて、ChatGPTの公式モバイルアプリを使用しているユーザーが最も頻繁に遭遇するエラー画面が「File stream access denied(ファイルストリームへのアクセスが拒否されました)」というものです。スマートフォンを動かしているOSは、セキュリティを最優先にするため、各アプリを「サンドボックス」と呼ばれる完全に隔離された砂場のような環境に閉じ込めて実行しています。
例えば、ChatGPTアプリが生成したPDFを、iPhoneの「ファイル」アプリや、Androidの「ダウンロード」フォルダという、デバイス本体のコアなストレージ領域に直接書き込もうとします。しかし、インストール時にユーザーが「このアプリに写真やファイルへのアクセスを許可しますか?」というポップアップに対して「許可しない」を選んでいたり、後から設定でオフにしていたりすると、OSのカーネルレベルでこの書き込みプロセスが問答無用で拒絶されます。アプリ側はファイルをダウンロードしたくても、スマホ本体が「ダメです」と弾き返してしまうわけですね。
古いOSバージョンとAPIの互換性問題
OSのアップデートを怠っていませんか?
iOSやAndroidのバージョンが古すぎる(例えばiOS 14.0未満やAndroid 8.0未満など)場合、ChatGPTアプリがファイルをやり取りするために要求する最新の「ファイルストリームAPI」と、スマホ側の古いシステムが噛み合わず、権限うんぬん以前に機能自体がクラッシュしてしまうという制約も存在します。
解決策としては、まずスマートフォンの「設定」アプリを開き、ChatGPTアプリの項目から「ストレージ」や「ファイルとメディア」へのアクセス権限がオン(すべてのファイルを管理できるよう許可)になっているかを必ず確認してください。それでも解決しない場合は、OS自体を最新バージョンにアップデートするか、一時的な回避策として、アプリではなくSafariやChromeなどの「Webブラウザ」からChatGPTにログインしてダウンロードを試みてください。Webブラウザであれば、すでにOSからダウンロード権限を与えられているため、すんなりとファイルが保存できるケースが非常に多いです。
PDFやエクセル生成時の文字コード不整合
「ファイルのダウンロード自体は100%完了したのに、いざ開いてみたら中身が宇宙語みたいになっていて読めない!」という経験、ありますよね。あるいは、特定の形式のファイルだけがダウンロード中に必ずエラーを吐くといった事象です。実は、ユーザーが要求するファイル形式(PDF、Excel、CSVなど)の構造や、そのファイルに名付けられた文字そのものが、システムの内部で深刻なバグを引き起こしているケースが多々あります。
UTF-8とShift-JISの永遠のすれ違い
「ChatGPT エクセル ダウンロードできない(または文字化けする)」という課題の多くは、文字のエンコーディング(コンピューターが文字を認識するためのルール)の違いに起因しています。ChatGPTのバックエンドは、国際標準であり世界中で最も広く使われている「UTF-8」という文字コードをデフォルトとしてデータを出力します。一方で、日本のビジネス環境で圧倒的なシェアを誇るMicrosoft Excelは、昔から使われている「Shift-JIS(シフトジス)」という日本独自のエンコーディングを優先して読み込もうとする頑固な仕様を持っています。
この結果、ChatGPTが綺麗に作成してくれた「UTF-8のCSVファイル」を、ユーザーがそのままダブルクリックしてExcelで開くと、Excel側が「これはShift-JISだ」と勘違いして読み込むため、日本語の部分だけが完全に文字化けして解読不能な状態になってしまうのです。これを防ぐためには、Excelの「データ」タブから「テキストまたはCSVから」を選択し、読み込みウィザードで元のファイルが「UTF-8」であることを手動で指定してあげるという、ひと手間が必要になります。
日本語ファイル名によるURLエンコードのパースエラー
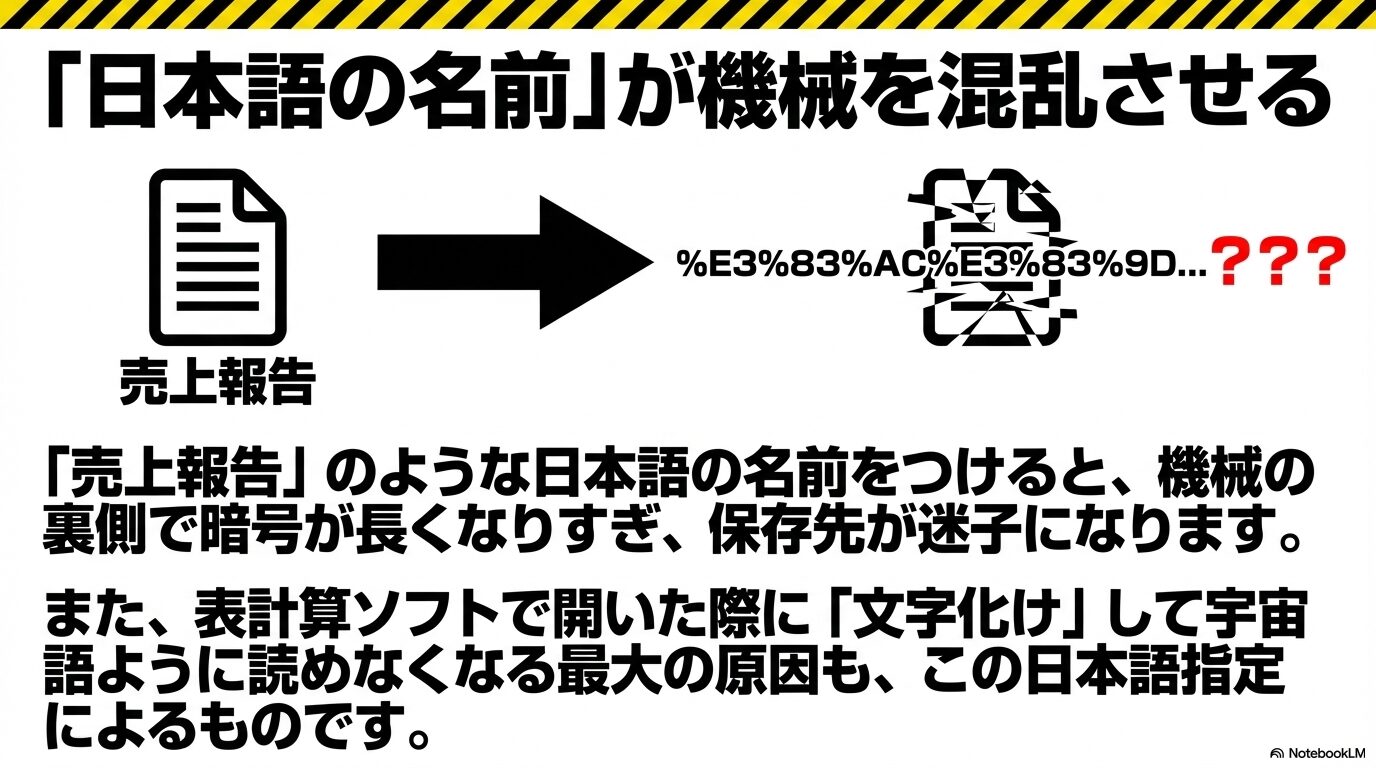
マルチバイト文字によるシステムの混乱
プロンプトで「『四半期売上レポート.pdf』という名前で出力して」と、日本語(マルチバイト文字)やスペース、絵文字を指定すると、ダウンロード用のURLが生成される際に、文字列が異常に長く複雑な記号(%E3%83%AC%E3…のようなパーセントエンコーディング)に変換されます。
一部のブラウザ環境やOSでは、この長すぎるURLのパース(解析)に失敗し、対象ファイルの居場所を見失ってしまいます。「準備ができました」と表示されているのにリンクが機能しない場合、このファイル名のエンコードエラーが原因であることが非常に多いです。システムの裏側では、目に見えない文字コードの不整合が、ダウンロードというシンプルな行為を複雑に邪魔しているということを覚えておいて損はありません。
Canvas機能特有のエラーと非表示問題
ChatGPTの基本チャット画面とは別に、プログラミングコードの記述や長文のドキュメント作成に特化した並行作業用のインターフェースとして「Canvas(キャンバス)」機能が登場しました。左側にチャット、右側に広大なエディタが表示される非常に画期的なツールですが、このCanvas機能を利用した際のエクスポート(ダウンロード)や画面表示に関するトラブルも、世界中で多数報告されています。
複雑なUI描画スクリプトと通信の断絶
Canvas機能は、従来のシンプルなテキストチャットとは異なり、Reactなどの高度なフロントエンド・フレームワークを用いて、ユーザーの入力とAIの修正をリアルタイムに同期させる複雑な仕組みで動いています。そのため、先ほど「ブラウザ拡張機能と通信経路の干渉」の項目でも触れたように、広告ブロッカーやプライバシー保護拡張機能の影響を極めて強く受けます。
Canvasを起動しようとした瞬間に画面が真っ白になってしまったり、「Network error」という赤いポップアップが頻発したりする主な原因は、Canvasがバックエンドと同期するために用いる特定の「WebSocket通信」や「APIエンドポイント」が、拡張機能や企業ファイアウォールによって不正な通信とみなされ、遮断されているからです。リアルタイム通信が切断されている状態では、右側のエディタに書き込まれた内容をローカルファイル(MarkdownやPDF、スクリプトなど)としてエクスポートしようとしても、データがサーバー側とうまく連携できず、ダウンロード処理が途中でストップしてしまいます。
モデル選択の不整合によるUI破綻
Canvasは対応モデルが限定されている
Canvas機能は、特定のモデル(GPT-4o with Canvas、あるいは後継のCanvas専用モデル)でのみ正常に稼働するように設計されています。
チャットの途中でシステムが重くなり、自動的に別のモデル(軽量モデルなど)に切り替わってしまったり、ブラウザのキャッシュに不具合が生じて古いインターフェースが読み込まれたりすると、CanvasのUIそのものが破綻します。この状態になると、エクスポートボタンを押しても無反応になったり、古いバージョンのテキストしかダウンロードされなかったりします。Canvas機能でダウンロードの不具合に遭遇した場合は、まずブラウザの「シークレットウィンドウ(プライベートブラウズモード)」を開き、拡張機能の影響をすべて排除したクリーンな状態で再度ログインして試してみるのが、最も確実で素早い解決アプローチとなります。それでもダメなら、Google ChromeからMicrosoft Edgeなど、根本的に異なるブラウザへ一時的にお引越ししてみるのも非常に効果的ですね。
ChatGPTでファイルをダウンロードできない時の対策
ここまで、ファイルがダウンロードできない様々な原因について深く掘り下げてきました。では、実際にエラーに直面した時、私たちはどう動けばいいのでしょうか。ここからは、今すぐ試すことができる実践的な解決策と、少し高度だけれど確実にデータを取り出せるプロンプトのテクニックを5つのステップで解説していきます。上から順に試していけば、大抵の問題はクリアできるはずです。

特定のファイル名指定によるエラー回避
ダウンロードトラブルに直面した際、一番最初に試していただきたい、最も簡単で即効性の高いアプローチが「ファイル名の英語指定」です。先ほど原因のセクションでもお話しした通り、日本語(マルチバイト文字)を含んだファイル名は、システムがダウンロードリンク用のURLを生成する際に文字化け(エンコードエラー)を引き起こしやすく、ファイルが迷子になる最大の要因の一つです。
プロンプト一行でシステムを正常化する
もし「ファイルの準備ができました」と言われたのに、リンクをクリックしてもエラーになる、またはボタンが無反応な場合は、焦らずにチャット欄へ以下のようなプロンプト(指示文)を入力して、ファイルの再生成を要求してみてください。
コピペで使える魔法のプロンプト
「ダウンロードできません。ファイル名を英語(半角英数字とアンダースコアのみ)にして、もう一度ファイルを作成してください。」
(英語入力の場合: “I can’t download the file. Please rename the file using only English letters and try again.”)
この明確な指示を与えることで、ChatGPTは「売上データ_2026.csv」といったバグを起こしやすい名前から、「sales_data_2026.csv」といった、OSやブラウザを選ばない互換性の高いプレーンなファイル名を生成してくれます。URLに日本語などの複雑な文字が含まれなくなるため、ブラウザがリンクを正しく解析(パース)できるようになり、すんなりとダウンロードが完了する確率が劇的に跳ね上がります。
また、ファイルの拡張子(.xlsx や .csv など)が抜けていてOSが開くソフトを認識できないケースもあるため、「必ず正しい拡張子をつけてください」と一言添えるのも、地味ですが非常に有効なテクニックです。多くのユーザーが、この一行のプロンプトを追加するだけで長時間のイライラから解放されていますので、まずは騙されたと思って試してみてくださいね。

Base64エンコードを用いたデータ直接出力
ブラウザの不具合でもなく、通信環境の問題でもなく、どうしても通常のダウンロードリンク(クラウドの一時URL)が機能しないという「絶望的な状況」に陥ることもあります。特に会社の厳しいセキュリティ環境下などでよく起きます。そんな時でも成果物を確実に取り出すための、少し専門的ですが極めて強力な「裏技」が存在します。それが「Base64(ベースロクヨン)エンコード」を利用したデータ抽出法です。
ファイルを「文字列」に変換してトンネルを抜ける
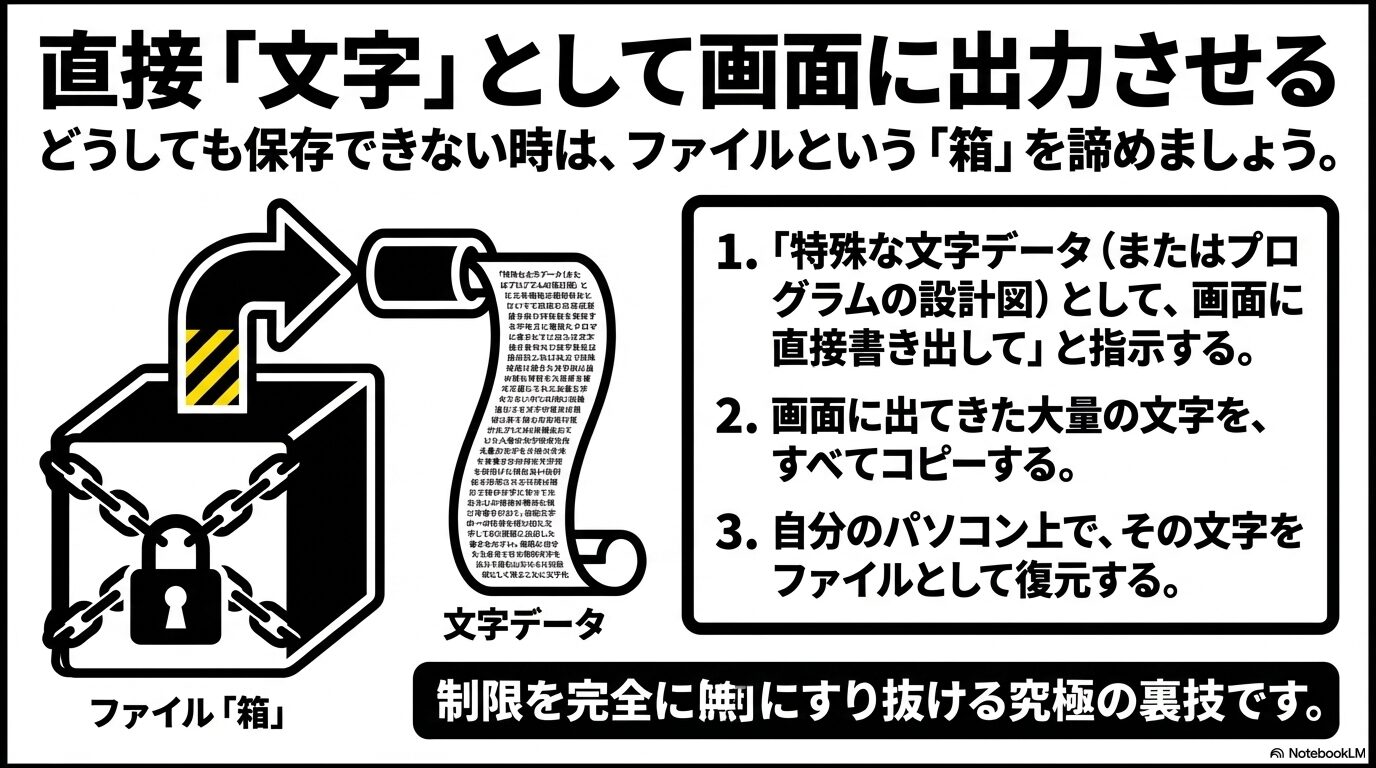
ファイルを物理的な「データ塊」としてダウンロードできないのであれば、ファイルの中身を純粋な「ただのテキスト文字列」に変換して、チャット画面上に直接出力させ、自分の手元で再びファイルの形に組み立て直すという逆転の発想です。Base64とは、画像やPDF、ZIPなどの複雑なバイナリデータを、アルファベットや数字などの印字可能な64種類の文字だけで表現する、世界標準のデータ変換規格のことです。
ChatGPTの「テキストを出力する機能」自体は、どんなに重い通信制限下でも確実に機能しています。つまり、ダウンロードインフラを経由せずに、テキストチャットという細い糸を使ってデータを安全に輸送する「トンネル」として利用するわけです。
具体的な抽出ステップ
Base64を使ったファイルの復元手順
- ChatGPTに対して、「先ほど生成したファイルをBase64でエンコードし、その文字列をコードブロックとして画面に出力してください」と指示します。
- ChatGPTが、「iVBORw0KGgoAAAANSUhEUgAAA…」のような、ランダムに見える大量の文字列を出力し始めます。
- この文字列を、最初から最後まで1文字も漏らさずにコピーします。
- ブラウザで「Base64 デコード オンライン」と検索し、無料の変換サイト(Codebeautifyなど)を開きます。
- コピーした文字列を貼り付け、元の拡張子(.pngや.pdfなど)を指定してデコード(復号)し、手元のパソコンに保存します。
この手法を用いれば、システム側のダウンロード制限やネットワークの干渉を一切無効化してデータを取り出すことが可能です。ただし、注意点として、バイナリデータを文字列化するとデータ量が元の約1.3倍に膨張してしまいます。そのため、数MBを超えるような大容量ファイルにこの手法を使うと、ChatGPTの「1回あたりの最大出力文字数(トークン制限)」に引っかかり、出力が途中でプツンと途切れてしまうリスクがあります。あくまで、軽量な文書ファイルや小さな画像に対する「最後の切り札」として活用するのが良いかなと思います。
Pythonコードによるローカル環境生成
データ分析の結果や、複雑なグラフ、あるいは長大なドキュメントをファイル化したい場合、先ほどのBase64よりもさらにスマートでエンジニアライクな解決策があります。それは、ChatGPTのサーバー上でファイルを作らせるという行為自体を完全に放棄し、「目的のファイルを生成するためのソースコード(設計図)」だけを書いてもらい、自分のパソコン上でその設計図を組み立てるというアプローチです。
サーバーの制限を無視して手元で作る
例えば、あなたが数万行のデータ処理を経てPDFレポートを作成しようとしたとします。これをChatGPT側でやらせると、処理時間が長すぎてタイムアウト(エラー)になる確率が非常に高いです。そこで、発想を変えます。
設計図をもらうプロンプトの例
「分析したデータ結果をもとに、PDFファイルを生成するPythonコードを作成してください。データはスクリプト内に直接書き込むか、ローカルのCSVを読み込む処理として記述してください。」
このように指示すると、ChatGPTはファイルの完成品ではなく、「このコードを実行すれば、あなたのパソコンの中にPDFファイルが出来上がりますよ」というPythonのスクリプト(.py)を出力してくれます。この手法の最大のメリットは、重い計算やファイルの生成作業を、ChatGPTのサーバー(クラウド)ではなく、あなた自身のパソコン(ローカル環境)のCPUとメモリを使って行う点にあります。
出力されたコードをコピーして、ご自身のPCのテキストエディタ(メモ帳など)に貼り付け、`report_generator.py`といった名前で保存します。あとは、コマンドプロンプトやMacのターミナルを開き、`python report_generator.py`と打ち込んで実行するだけです。(※事前にPythonのインストールや、必要なライブラリのインストールが必要です)。
少しプログラミングの知識が必要になりますが、この方法を使えば、OpenAIの厳しいダウンロード容量制限や、会社のネットワークファイアウォールの干渉を100%回避することができます。エラーに悩まされることなく、安全かつ確実に目的のファイルをローカル環境へ直接生成できるため、業務で頻繁にデータを扱う方にとっては、ぜひマスターしておきたい究極の代替手法と言えるでしょう。
アカウントのデータコントロール設定修正
様々なテクニックを駆使しても、そもそも「ダウンロードリンクすら生成されない」「ボタンを押してもウンともスンとも言わない」という場合、あなたのChatGPTアカウントの「プライバシー設定」が、ダウンロード機能をサイレントにブロックしてしまっている可能性があります。ここを見落として何時間も悩むユーザーが非常に多いため、必ずチェックしていただきたい項目です。
「モデル改善」オプションとファイル生成の密接な関係

ChatGPTの画面左下にある自分のアイコンをクリックし、「設定(Settings)」から「データコントロール(Data Controls)」というメニューを開いてみてください。そこに、「みんなのためにモデルを改善する(Improve the model for everyone)」というトグルスイッチ(オン・オフの切り替えボタン)があるはずです。企業で利用している方や、プライバシー意識の高い方の多くは、自分の会話履歴をAIの学習に使われないよう、この設定を「オフ(無効化)」にしていると思います。
一見、ファイルのダウンロードとは何の関係もない設定に見えますよね。しかし、実はこの現象の背景には、ユーザーデータを機械学習のトレーニングから除外するための処理パイプラインが、一時ファイルのホスティングプロセスとシステム的に密結合しているという、OpenAI側の構造的な問題(バグに近い仕様)が存在しているのです。
(出典:OpenAI『Data Controls FAQ』)
学習への利用を拒否する設定が有効(オフ)になっていると、ファイルをサーバーの一時保存先へ書き込む権限や、セッション間でファイルを安全に受け渡すために必要なトークン(許可証のようなもの)の生成が、セキュリティの兼ね合いで阻害されてしまうケースが多数報告されています。結果として、フロントエンドの画面上には親切にダウンロードボタンが表示されているのに、裏側のシステムでは「ファイルの持ち出しは許可されていません」という不整合が生じ、ダウンロードが完全に失敗してしまうのです。
設定変更によるトラブルシューティング手順
もしどうしてもファイルが取り出せない場合は、以下の手順を試してください。
- 一時的に「みんなのためにモデルを改善する」をオン(有効)にする。
- 新しいチャット(セッション)を開き直し、再度ファイルの生成を指示する。
- ダウンロードが成功し、手元にファイルが保存できたことを確認する。
- 速やかに設定を元のオフ(無効)に戻す。
この手順を踏むことで、ブロックされていた権限が一時的に解放され、すんなりとダウンロードできることが多々あります。根本的な解決にはシステム側のアップデートを待つしかありませんが、緊急時にファイルを取り出したい場合には、非常に有効なワークアラウンド(代替策)となります。
ChatGPT ファイルがダウンロードできない問題のまとめ
いかがでしたでしょうか。ChatGPTでファイルがダウンロードできないという事象は、「ただシステムが重いだけ」という単純なものではなく、2026年の最新制限によるリソースキャップ、バックエンドの揮発性(有効期限)、私たちが使うブラウザのセキュリティ仕様との衝突、さらにはアカウントのプライバシー設定に至るまで、実に多層的な要因が複雑に絡み合って発生していることがお分かりいただけたかと思います。
最後に、トラブルシューティングの流れをわかりやすく3つのフェーズにまとめておきますね。問題に直面した時は、焦らず以下の順番でアプローチしてみてください。
段階的なトラブルシューティングのまとめ

- フェーズ1(即効性重視):まずは一番多い「一時リンクの有効期限切れ」や「ファイル名の文字化け」を疑いましょう。チャット上で「ファイル名を英語の半角英数字に指定して、もう一度生成して」とプロンプトで指示し直すだけで、半数以上の問題はあっさり解決します。
- フェーズ2(環境の見直し):それでもダメな場合は、あなたの環境側に原因があるかもしれません。ブラウザの広告ブロッカーを一時停止するか、シークレットウィンドウを使って拡張機能の影響をなくしてみてください。スマホアプリ版でエラーが出る場合は、Webブラウザ(SafariやChrome)からChatGPTにログインしてダウンロードを試みるのが吉です。
- フェーズ3(最終手段):利用制限(1日3ファイルや、10GBストレージ上限)に達していないか、データコントロール設定が影響していないかを確認します。どうしても物理ファイルとしてダウンロードできない場合は、Base64エンコードによるテキスト出力への切り替えや、Pythonコードを出力させて自身のパソコンで生成するといった、少し高度な裏技を駆使してデータを救出しましょう。
AIプラットフォームは急速に進化を続けているため、仕様変更によって新たなエラーが発生することもあるかもしれません。しかし、今回ご紹介したエラーの「裏側にある仕組み」を理解しておけば、どんな状況でも冷静に対処し、確実に必要なファイルを手元に取り出すことができるはずです。日々の業務や学習をAIでスムーズに進めるためにも、ぜひこの記事のノウハウを活用してみてくださいね。
※この記事で紹介している設定変更やシステムの挙動、プロンプトの効果は、将来的にOpenAIのアップデート等で変わる可能性があります。重要な業務データを扱う場合や、パソコン・スマートフォンのシステム設定を変更する際の最終的な判断は、IT部門の専門家にご相談いただくか、ご自身の責任で慎重に行っていただくようお願いいたします。