
こんにちは。AI index、運営者の「りょう」です。
ChatGPTを使っていて、議論が深まってきた一番いいところで突然「この会話は長さの上限に到達していますが、新しいチャットを始めて会話を続けることができます。」というエラーが出て止まってしまう経験はありませんか。長い文章を作成していたり、複雑なコードを書いてもらっている最中に、画面に表示される警告メッセージを見ると本当に焦りますよね。せっかく積み上げてきた文脈や前提条件が、新しいチャットに切り替えることで失われてしまうのではないかという不安もよくわかります。実はこの現象、単なる不具合ではなく仕組み上の明確な理由があるのです。今回は、このエラーが出る原因と、これまでの会話の内容をスムーズに引き継いで継続するための具体的なテクニックについて、私自身の経験も交えながらお話ししていきたいと思います。

- エラーが発生する技術的な背景とトークン消費の仕組み
- Web版ChatGPT特有の記憶容量の制限とAPIとの違い
- 会話の文脈を失わずに新しいチャットへ移行する具体的な手順
- 将来的にこの問題を回避するためのGPTsなどの高度な活用法
「この会話は長さの上限に到達していますが、新しいチャットを始めて会話を続けることができます。」が出る原因
まずは、なぜあのようなエラーメッセージが表示されて会話が強制的に中断されてしまうのか、その根本的な原因について見ていきましょう。ユーザーとしては「まだ話せるはずだ」と感じる場面でも、AIの裏側では物理的な限界を迎えていることがあります。これはOpenAIが意地悪で制限しているわけではなく、現在のAIモデルが抱える数理的な必然性と、サービスを安定して提供するための「容量の壁」が存在するからです。
ChatGPTの会話上限エラーが発生する仕組み
私たちが普段何気なく会話しているChatGPTですが、その頭脳である基盤モデル(Transformerアーキテクチャ)は、私たちが想像する以上に複雑な計算を行っています。このモデルの核心には「セルフアテンション(Self-Attention)」というメカニズムがあり、これは入力されたテキスト内のすべての言葉(トークン)が、他のすべての言葉とどのように関連しているかを常に計算し続けています。
ここで非常に重要になるのが、会話が長くなればなるほど、AIが処理しなければならない計算量が「足し算」ではなく「二乗」に近いペースで幾何級数的に増大していくという点です。例えば、会話の量が2倍になると、AIにかかる負荷は単純に2倍になるのではなく、4倍近くに跳ね上がります。これは、10人のパーティで全員と握手をするのと、100人のパーティで全員と握手をするのとでは、必要な手間が桁違いに変わるのと似ています。会話履歴という「参加者」が増えれば増えるほど、AIはその全員の関係性を把握し続けるために膨大なエネルギーを消費することになるのです。
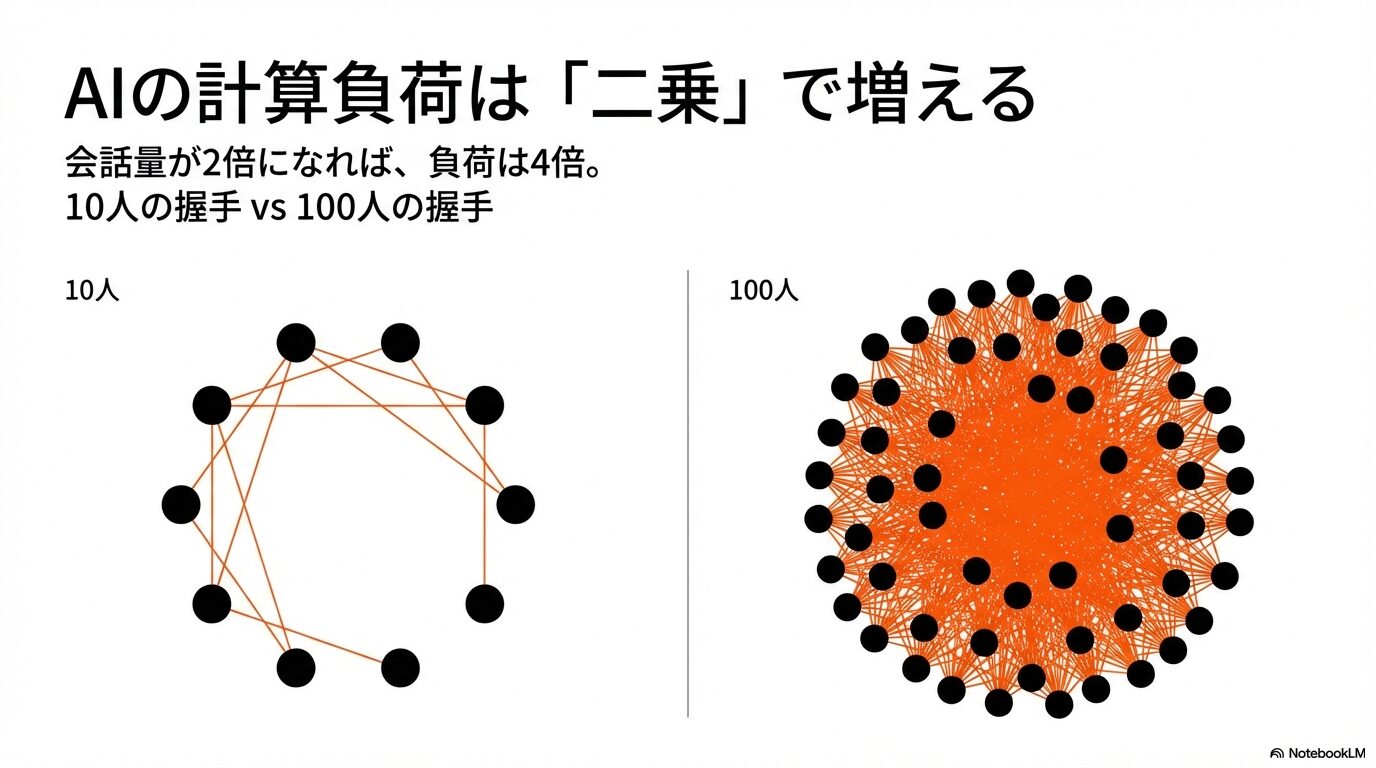
サーバーの負荷が爆発的に増えるのを防ぎ、すべてのユーザーに快適な応答速度(レイテンシ)を提供するために、OpenAI側で「これ以上は計算リソースを割り当てられません」という強制的なラインを引いています。これがあのエラーメッセージの正体です。
また、この制限はコストの問題とも直結しています。無限に会話を続けさせることは、現在の計算機の能力では天文学的なコストがかかってしまうため、サービスを維持するためにも、どこかで「打ち切り」を設定せざるを得ないというのが実情なのです。
ChatGPTのトークン上限と日本語の制約
ChatGPTの制限について調べると必ず出てくる「トークン」という言葉ですが、これはAIがテキストを処理する際の最小単位のことです。私たち人間は「文字」や「単語」で文章を理解しますが、AIはテキストを数値の羅列(トークン)に変換して処理しています。実はここに、英語圏のユーザーと私たち日本語ユーザーの間で、構造的な「不公平」とも言える差が存在しています。
英語の場合、例えば “apple” という単語は1つのトークンとして扱われることが多く、非常に効率的です。しかし、日本語の場合は事情が異なります。漢字やひらがなは、バイトペアエンコーディング(BPE)という変換ルールにおいて複雑な扱いを受けることが多く、特に古いモデルや最適化されていないトークナイザーでは、たった1文字の漢字を表すのに複数のトークンを消費してしまうことがありました。最新のGPT-4oでは「o200k_base」という新しいトークナイザーが導入され、この効率はかなり改善されましたが、それでも英語に比べると「意味の密度」に対する「トークン消費量」のバランスは不利な傾向にあります。
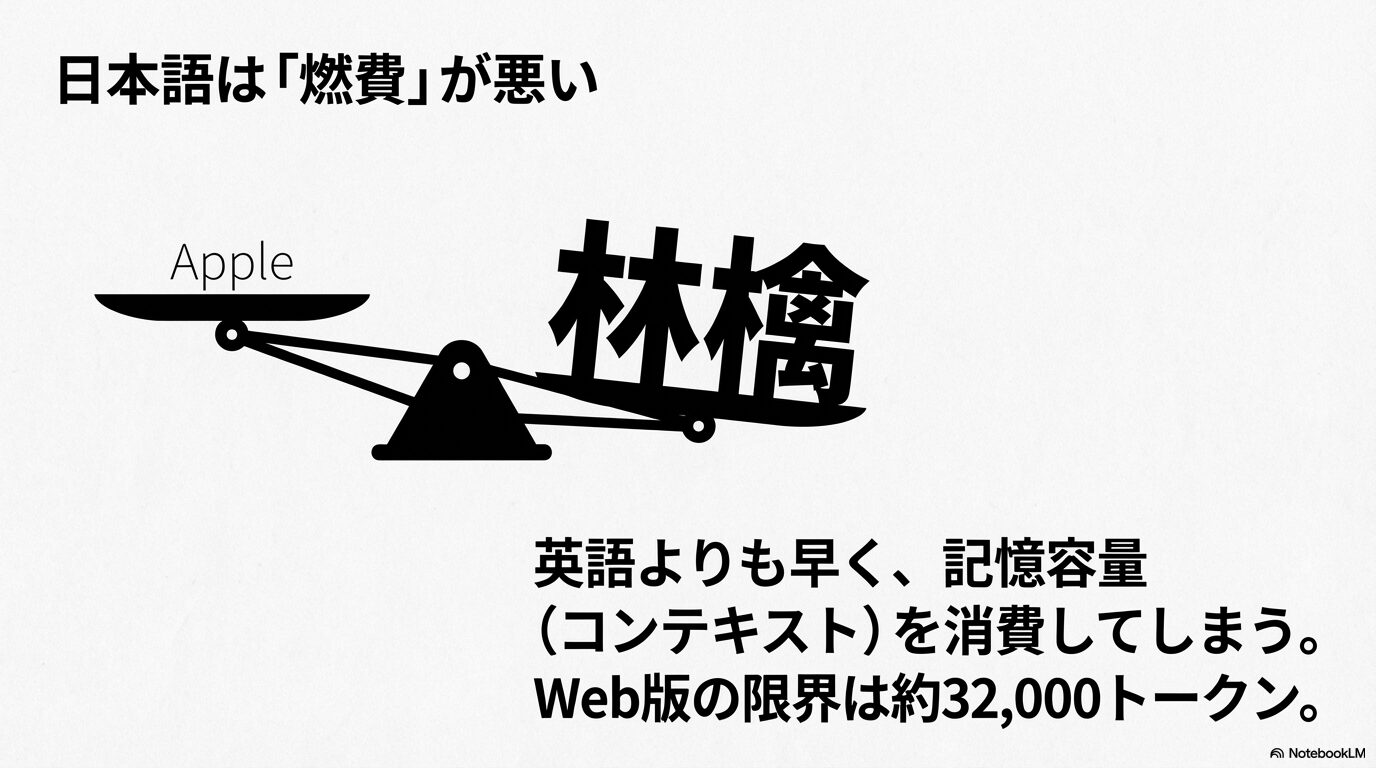
ユーザーが「まだそんなに長く話していない、文字数にして数千文字程度だ」と感じていても、システム内部では日本語の特性によって予想以上にトークンが消費されており、知らず知らずのうちに制限の限界値(閾値)に達してしまっているケースが多発します。これが、日本人のユーザーが頻繁にこのエラーに遭遇してしまう大きな要因の一つです。
ChatGPTの記憶限界とWeb版の仕様
AIに詳しい方なら、「GPT-4 TurboやGPT-4oは、APIなら128kトークン(文庫本300冊分以上)ものコンテキストウィンドウを持っているはずだ」と疑問に思うかもしれません。確かに、開発者が利用するAPIの世界では、それだけの膨大な情報を一度に処理することが可能です。しかし、私たちが普段利用しているWebブラウザ版のChatGPT(ChatGPT PlusやTeamプランなど)では、仕様が大きく異なります。
Web版(ChatGPT公式のチャット画面)では、ブラウザのメモリ消費を抑えて動作を軽くしたり、サーバー全体の負荷を分散させたりするために、実質的な記憶容量(コンテキストウィンドウ)が約32,000トークン程度に制限されているという検証結果が多く報告されています。
これはAPIの理論値の4分の1程度です。さらに、最近のユーザー検証では、トークン数とは別に「やり取りの回数(ターン数)」自体にも見えないハードキャップ(上限)が存在する可能性が指摘されています。ある検証によると、トークン数に余裕があったとしても、約1,300回程度のやり取りを超えると、データベースの管理上の制約により会話が強制的に停止し、それ以上の履歴を追加できなくなる現象が確認されています。つまり、どんなに短文で会話をしてトークンを節約したとしても、長く使い続けたチャットはいずれ必ず「寿命」を迎える運命にあるということです。
新しいチャットを始めると文脈が消える問題
システムから「この会話は長さの上限に到達していますが、新しいチャットを始めて会話を続けることができます。」と提案されても、多くのユーザーが素直に従いたくないと感じるのはなぜでしょうか。それは、新しいチャットが「真っ白な状態」であり、これまで築き上げてきた共有知識がゼロになってしまうことへの恐怖があるからです。
長い会話を通じて、AIは私たちのプロジェクトの背景、独特の専門用語、好みの文体、あるいは「こういう回答はしないでほしい」といった暗黙のルールを学習し、チューニングされた状態になっています。これを「コンテキスト(文脈)」と呼びますが、これは単なるテキストデータの集合体以上の、いわばチャットルームに宿った「魂」のようなものです。新しいチャットに移動するということは、この魂を置き去りにして、記憶喪失の別人に一から説明し直すようなものです。
「また最初から前提条件を説明し直すのか…」という徒労感と、以前のような精度の高い回答が得られなくなるかもしれないという不安こそが、私たちがこのエラーメッセージに対して強いストレスを感じる最大の理由かなと思います。だからこそ、単にチャットを新しくするのではなく、「いかにして文脈を移植するか」が重要になるのです。
エラーが出る前に発生する予兆と挙動
実は、あのアラートが出て完全に操作不能になる前に、AIの方でも「そろそろ限界が近いです」というサイン(予兆)を出していることがよくあります。これを見逃さずに早めに対処することで、突然の中断によるパニックを防ぐことができます。
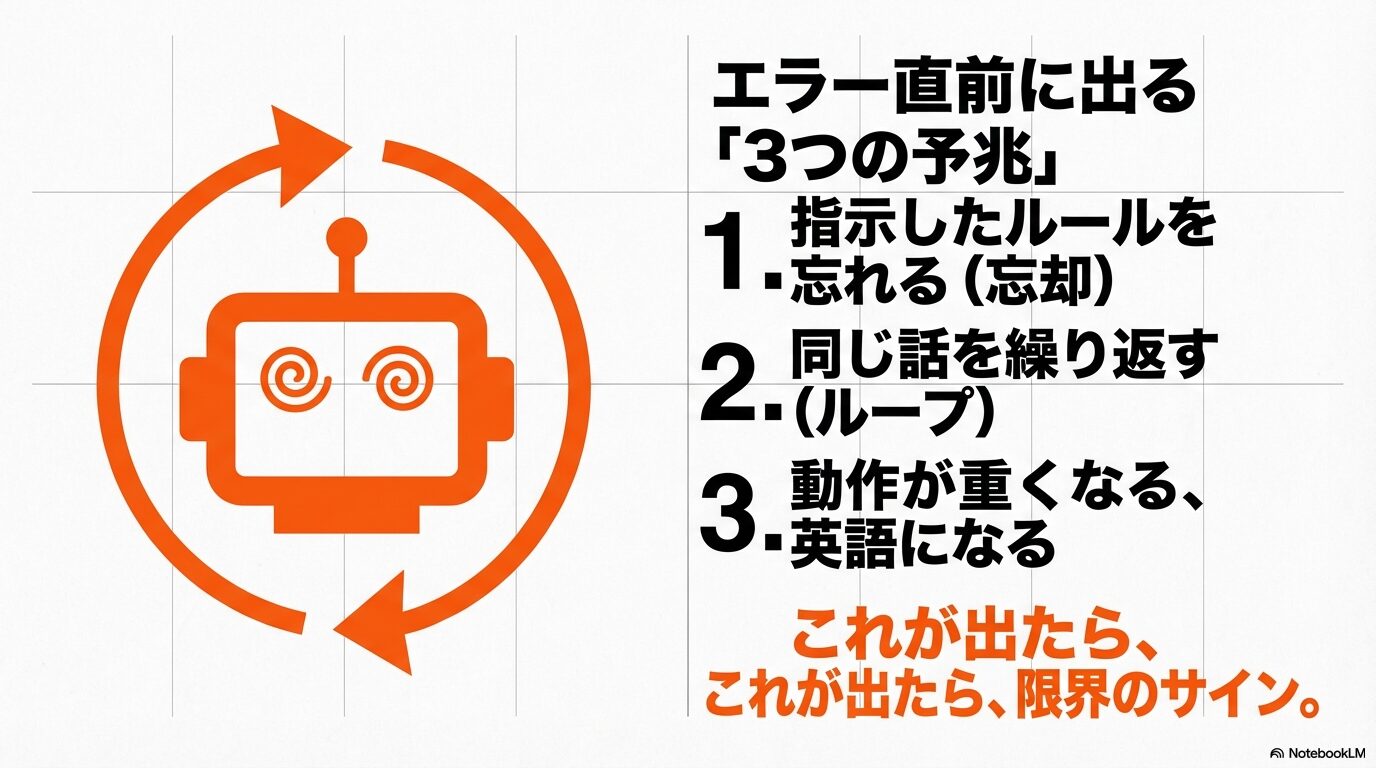
最も典型的な予兆は「忘却」です。会話の初期に指示したはずの「出力フォーマット」や「役割定義(あなたはプロの編集者です、など)」をAIが無視し始めたり、忘れたりする現象です。これは「スライディングウィンドウ」と呼ばれるメモリ管理の仕組みにより、新しい情報を入れるために古い情報がところてん式に押し出され、コンテキストから消去され始めた証拠です。
次に現れるのが「ループ」や「品質の低下」です。AIが同じフレーズを何度も繰り返したり、回答の論理が破綻し始めたりします。そして最終段階では、「Network Error」や「Something went wrong」といった接続エラーが頻発するようになります。これは、回答を生成しようとしても、入力と出力を合わせたトークン数がサーバーの許容範囲を超えてしまい、タイムアウト(時間切れ)を起こしている状態です。これらのサインが出たら、強制停止のエラーが出るのは時間の問題ですので、直ちに「引っ越し」の準備を始める必要があります。
「この会話は長さの上限に到達していますが、新しいチャットを始めて会話を続けることができます。」の解決策
では、実際にこのエラーに直面したとき、あるいは直面しそうな予兆を感じたときに、どうすればこれまで築き上げた「文脈」という資産を守りながら会話を継続できるのでしょうか。私が普段の実務で実践している、効果実証済みの具体的な方法をレベル別にご紹介します。
ChatGPTの要約プロンプトで内容を継承
最も基本的でありながら、即効性が高いのが「ブリッジ・サマリー(橋渡しのための要約)」を作成する方法です。しかし、単に「これまでの会話を要約して」とAIに頼むだけでは不十分です。普通の要約では「何について話したか」というあらすじしか残らず、細かな決定事項やルールが抜け落ちてしまうからです。次につなげるためには、構造化された「引き継ぎ書」を作らせる必要があります。

エラーが出る直前、あるいは動作が重くなってきた段階で、以下のプロンプトを実行してみてください。
【推奨:引き継ぎ用プロンプト】
「現在、会話の長さが上限に近づいています。新しいチャットでこの議論をシームレスに継続するために、以下の要素を含む詳細な『引き継ぎ用サマリー』を作成してください。

1. 現在の到達点と結論: これまでに決定した事項の箇条書き。
2. 未解決の課題: まだ議論が終わっていない、解決していない問題点。
3. ユーザーの好みと制約: 私がこれまでに指定したフォーマット、トーン、除外事項などのルール。
4. 次のアクション: 新しいチャットで直ちに取り組むべきタスク。
この出力は、次のチャットの冒頭に入力するシステムプロンプトとして機能するように記述してください。」
このプロンプトを実行すると、AIはこれまでの文脈を圧縮した「種(シード)」を出力してくれます。これをコピーして、新しいチャットの最初のメッセージとして貼り付けるだけで、AIは「なるほど、先ほどの続きですね」と即座に理解し、まるで会話が途切れなかったかのように振る舞ってくれます。このひと手間で、文脈の喪失を最小限に抑えることができます。
過去の会話を編集してエラーを回避する方法
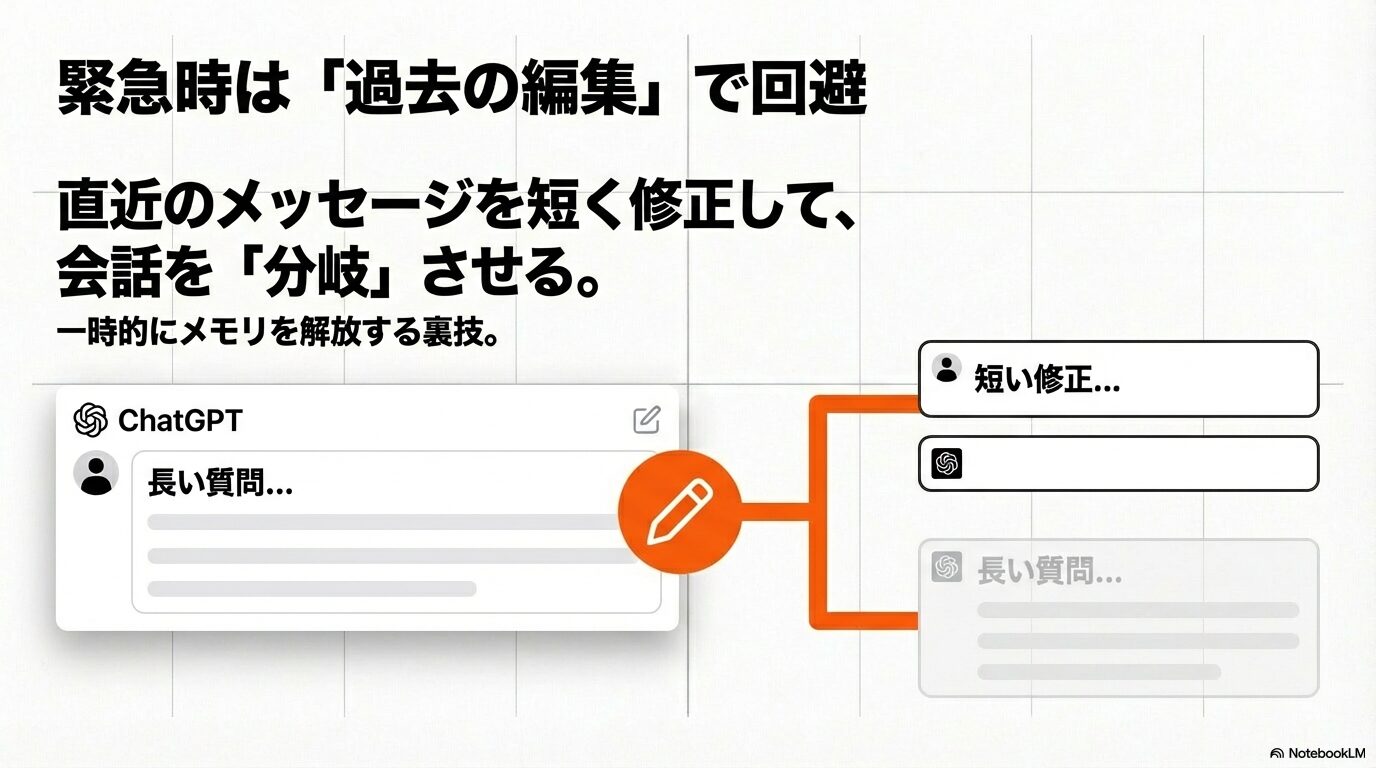
「あと1回だけ質問したいのに、エラーが出てしまって要約すら作れない!」という緊急事態に陥ることもあります。そんな時に使えるのが、過去のメッセージを「編集」して会話を分岐させる裏技です。
ChatGPTのインターフェースには、自分の発言の右側に「鉛筆アイコン(編集ボタン)」がついています。これをクリックして、エラーが出る原因となった直近の重たいやり取り(例えば、大量のコードを出力させた指示など)の前に戻り、メッセージ内容を短く修正したり、「簡潔に答えて」と指示を変えて「保存して送信」を押してみてください。
この操作を行うと、編集した時点より後の会話履歴は現在のビューから消え(履歴には残りますが)、新しい分岐(ブランチ)が作成されます。これにより、直近で消費されていた大量のトークンが一時的に解放されるため、エラーを回避して最後の質問を通すことができる場合があります。
これはあくまで一時的な応急処置であり、根本的な解決ではありませんが、どうしても最後の回答を引き出したいときや、要約プロンプトを走らせるための「一枠」を確保したいときには、非常に有効なテクニックです。
ChatGPTの履歴エクスポートを活用する
長編小説の執筆や、大規模なアプリケーション開発など、要約してしまうと重要な「細部」が失われてしまうケースもあります。そのような場合は、会話データを丸ごと抜き出して、外部記憶として再利用する方法が最適です。
ChatGPTの設定(Settings)にある「データコントロール(Data Controls)」から「データをエクスポート(Export Data)」を選択すると、登録しているメールアドレス宛に全会話履歴が入ったZIPファイルが届きます。この中にある conversations.json というファイルには、過去のすべてのチャットのテキストデータが保存されています。
このJSONファイル(あるいはそれをテキストに変換したもの)を、新しいチャット(GPT-4oなどファイル読み込みに対応したモデル)の添付ファイルとしてアップロードし、「このファイルはこれまでの私たちの議論の全履歴です。まずこれを熟読し、すべての文脈を把握した上で、続きの議論を始めましょう」と指示します。こうすることで、AIはアップロードされたファイルを「参照用データベース」として扱い、アクティブなメモリを消費することなく、過去の膨大なログに基づいた回答が可能になります。これは専門的にはRAG(検索拡張生成)と呼ばれる技術を応用した、上級者向けのアプローチです。
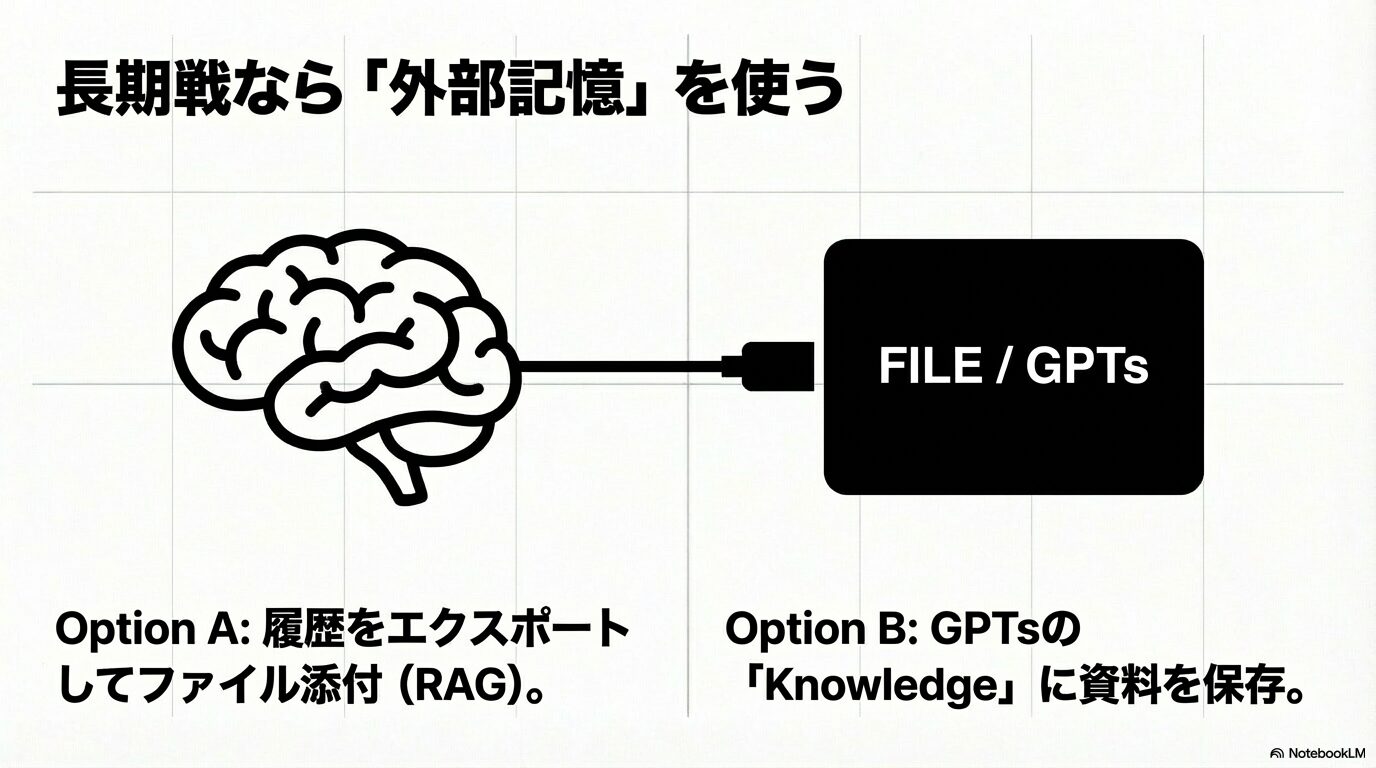
GPTsに知識を保存して会話を続ける
もし、特定のテーマ(例:自社のブログ記事作成、特定のプログラミングプロジェクトなど)について、チャットを変えながら何度も長い会話をするのであれば、その都度ファイルをアップロードするのは面倒です。そこで役立つのが、自分専用のカスタムAI「GPTs」を作成することです。
GPTsの作成画面(Configure)には、「Knowledge(知識)」というセクションがあり、ここにテキストファイルやPDF資料をアップロードしておくことができます。先ほどのエクスポートデータや、プロジェクトの要件定義書、これまでの決定事項をまとめたドキュメントをここに登録しておきましょう。
こうすることで、新しいチャットを開始するたびに、AIが自動的にその「Knowledge」を参照してくれるようになります。会話履歴というすぐに消えてしまう「短期記憶」ではなく、Knowledgeという永続的な「長期記憶」に情報を移すことで、会話が長さの上限に達してリセットされても、AIのキャラクターや前提知識はそのまま維持されます。頻繁に同じ作業をする方にとっては、これが最も恒久的でスマートな解決策と言えるでしょう。
まとめ:「この会話は長さの上限に到達していますが、新しいチャットを始めて会話を続けることができます。」を克服する
今回は、ChatGPTを使い込んでいるユーザーなら誰もが一度は悩まされる「会話の長さ上限エラー」について、その技術的な原因から、文脈を守るための実践的な解決策までを深掘りしました。
このエラーは、現在のAIモデルが持つ計算資源の制約上、避けては通れない「仕様」です。しかし、それが作業の「終わり」を意味するわけではありません。エラーが出る仕組みを理解し、適切なタイミングで「ブリッジ・サマリー」を作成したり、ファイルを活用して記憶を外部化したりすることで、私たちは実質的に無限に会話を続けることが可能になります。

- エラーはAIの計算量が「二乗」で増えるのを防ぐための必然的な措置
- 日本語は英語に比べてトークン効率が悪く、Web版では32kトークン等の制限がある
- 「引き継ぎ用プロンプト」を使って、文脈の種を新しいチャットに移植するのが基本戦略
- 履歴のエクスポートやGPTsのKnowledge機能を活用すれば、より多くの記憶を保持できる
なお、各モデルの具体的なコンテキストウィンドウの仕様や制限については、OpenAIの公式ドキュメント(出典:OpenAI Platform『Models』)でも詳細を確認することができます。AI技術は日々進化しており、GoogleのGemini 1.5 Proのように100万トークンを超えるモデルも登場していますが、基本的な「記憶の管理術」は今後も重要なスキルであり続けるはずです。今回ご紹介したテクニックを駆使して、AIとの対話をより長く、より深く楽しんでいただければと思います。
